Un sistema de computo ?
Hemos hablado anteriormente del sistema LINUX, pero que es
un sistema de computo:
La palabra sistema procede del latín systēma, y este del
griego σύστημα (systema), identificado en español como "unión
de cosas de manera organizada".
Computo proviene del latín compŭtus, que es una cuenta o
cálculo.
La noción de cómputo también se utiliza en el marco de la
teoría de la computación, la rama de la matemática que se
especializa en las capacidades fundamentales de las
computadoras. Estas máquinas se encargan de utilizar modelos
matemáticos para hacer cómputos.
Entonces un sistema de computo es un
conjunto de elementos que interactúan entre si, como el
(hardware) para procesar y almacenar información de acuerdo a
una serie de instrucciones, como lo es el (software). Por
tanto significa organización, distribución y combinación
de los elementos que llegan a formar parte de un sistema de
computo.
Un sistema de cómputo consta de dos grupos de componentes:
Un sistema de computo en hardware puede estar integrado por:
Escáner
Teclado
Cámara de video (aquí una pagina
interesante donde podrás verificar si tu cámara web esta
lista para trabajar)
Ratón
Impresora
Tarjeta de audio, bocinas
Monitor
Tarjeta de video
Microprocesador
Tarjeta madre (Motherboard)
Memoria RAM
Unidad de DVD y/o CD
Disco duro
Unidad de disquete (actualmente en desuso)
Tarjeta de red
Módem (opcional)
Unidad de estado solido (SSD)
y para verificar que tu micrófono de la computadora este
funcionando bien usa esta pagina.
Un sistema de computo en software esta integrado por:
Todos los programas que son necesarios
para que el hardware tenga su propósito, sin el software el
hardware es un montón de tornillos tuercas circuitos sin un
fin en particular.
Detrás de cada aplicación, hay un lenguaje de programación
Las aplicaciones y servicios, parte vital de
nuestra vida digital, están escritas en diferentes lenguajes
de programación (las tripas del programa que no vemos y hacen
que este se comporte de la forma en que lo hace). Por ejemplo,
las apps de iOS están escritas con el lenguaje Swift mientras
que los desarrolladores de Andorid utilizan Java o Lua/Corona,
lo mas usual es Java, para realizar estos programas o apps
para celulares hay que primero aprender a programar en Java.
Linux está construido sobre la base de
lenguaje C y C++, y el Kernel de Linux -corazón de nuestras
distribuciones LINUX-
está escrito también ensamblador, pero fundamentalmente
en C++, un lenguaje con décadas de historia.
Los servicios de Internet por su parte están
formados por una combinación de CSS o HTML para el frontend
(cara visible de la web) y por otros como Python, C++, MySql,
MariaDB, JavaScript, o ASP.NET para el back-end o parte de
administración de las webs.
Así, por ejemplo, los usuarios del lenguaje
Python tienen la ventaja importante de requerir muchas menos
líneas de código para hacer cosas que también se pueden
conseguir con Java, C, C++, este ultimo es el preferido para
programación.
Al margen de muchas características
diferentes, algo que diferencia a simple vista a unos
lenguajes de otros es la cantidad de líneas de código que
requieren para funcionar.
UNIX es un sistema operativo multitarea y
multiusuario. La multitarea es muy útil, y una vez la haya
probado, la usará continuamente. Muchas de las características
que se tratarán en esta sección son proporcionadas por el
intérprete de comandos. Hay que tener cuidado en no confundir
UNIX (el sistema operativo) con el intérprete de comandos. El
intérprete de comandos proporciona la funcionalidad sobre el
UNIX.
El intérprete de comandos no es sólo un
intérprete interactivo de los comandos que tecleamos, es
también un potente lenguaje de programación, el cual permite
escribir guiones, que permiten juntar varias ordenes en un
archivo. El uso de los guiones (scripts) del intérprete de
comandos es una herramienta muy potente que le permitirá
automatizar e incrementar el uso de UNIX.
Apagar o
Reiniciar el SO Linux
En este punto nos preguntamos como debemos de apagar o
reiniciar el SO, pues bien hay varias manera de realizarlo:
1.-Uso del botón apagado desde GUI, en el extremo superior
derecha de la pantalla y a la derecha de la pantalla, el boton
que representa el encendido/apagado, hacemos clic ahi:

donde nos mostrara lo siguiente:

en la parte inferior hay 3 Iconos el del lado derecho al
pulsar sobre el, nos mostrara un menú adicional, a la mitad de
la pantalla:
Aquí seleccionamos la acción a realizar.
2.- Por nivel de Ejecución:
En los sistemas operativos informáticos basados en Unix,
init (abreviatura de inicialización) es el primer proceso que
se inicia durante el arranque del sistema informático. … El
kernel inicia la inicialización durante el proceso de
arranque; se producirá un pánico del kernel si el kernel no
puede iniciarlo. Por lo general, a Init se le asigna el
identificador de proceso 1, esto se realiza a nivel comando en
linea.
init 0
Básicamente, init 0 cambia el nivel de ejecución actual al
nivel de ejecución 0. shutdown -h puede ejecutarlo cualquier
usuario, pero init 0 solo puede ejecutarlo el superusuario.
Básicamente, el resultado final es el mismo, pero el apagado
permite opciones útiles que en un sistema multiusuario crean
menos enemigos.
| Nivel de ejecución |
Modo |
Acción |
0
|
Modo superior "Alto" (solo root)
|
Apaga el sistema desde la linea de
comandos
|
| 1 |
Modo de usuario único |
No configura interfaces de red, inicia demonios ni
permite inicios de sesión no root |
| 2 |
Modo multiusuario |
No configura interfaces de red ni inicia demonios. |
| 3 |
Modo multiusuario con conexión en red |
Inicia el sistema normalmente. |
| 4 |
Indefinido |
No utilizado / Definible por el usuario |
5
|
Modo Multiusuario
|
Inicia en modo grafico
|
6
|
Reincio
|
Reinicia el sistema, arrancando con el
modo predefnido
|
para conocer que nivel de ejecución tiene el
sistema:
[msantos@asus /]$ who -r
`run-level'
5 2022-08-23 05:42
[msantos@asus /]$
3.- Con el tradicional metodo de las 3 teclas Crtl-Alt-Del,
no muy recomendable pero solo en caso de emergencia (esto es
porque se debe de sincronizar el superbloque, aunque desde
CentOS 6, hay medidas de seguridad para evitar daños en el
superbloque)
4.- En CLI usar: sync, y después, init 6, o init 0.
Para continuar realiza el siguiente test 1.7:
NOTA: A partir de este punto la evaluacion
de las actividades seran relizando las actividades, capturar
patalla, y envio de evidencias al correo que se les indicara
(procediminro de captura de pantalla se explicara en el
momento de relizar la actividad)
El siguiente paso sera actualizar el
sistema, pero no te preocupes no hay problemas en al
actualización como en otros sistemas en la misma computadora.
Iniciamos una terminal y ejecutamos su - (superusuario, e
introduzca la contraseña de root que se establecio al inicio
de la instalación
Usaremos la Instrucción : dnf update -y
Explicaremos este comado en la siguiente unidad.
El proceso podría tardar algunos minutos porque es posible
que se actualicen hasta 1300 paquetes.
Terminado el proceso re iniciamos el
sistema, del lado derecho superior clic sobre la seccion que
se ve en la imagen, y abajo a la derecha clic sobre el icono
de encender/apagar, preguntara Cancelar Reiniciar Apagar:
El Reiniciar / Apagar cerrara todos las aplicaciones,
al volver a cargar el sistema abrimos una terminal,
Aplicaciones -> terminal.
Introducción a vi.
A pesar de su ergonomía muy limitada, Vi es
uno de los editores de texto más populares de los sistemas
Unix (con Emacs, nano y pico). En Linux, hay una versión
gratuita de Vi denominada Vim (Vi Improved [mejorada]). Vi
(que se pronuncia vi-ái) es un editor completamente en modo
texto, lo cual significa que todas las acciones se llevan a
cabo con la ayuda de comando de texto. Si bien en principio
este editor parece tener poco uso práctico, es muy eficaz y
puede ser muy útil en caso de que falle la interfaz gráfica.
La sintaxis para abrir vi es la siguiente:
vi <nombre_del_archivo>
Modos de vi
vi posee tres modos operativos:
-
Modo regular: Éste es el modo que introduce cada vez
que abre un archivo. Este modo permite la introducción
de comandos.
-
Modo de inserción: Este modo permite la inserción de
caracteres que se capturan dentro del documento. Para
pasar al modo de inserción, simplemente pulse la tecla
Insert en su teclado o la tecla i predeterminada.
-
Modo de reemplazo: Este modo le permite reemplazar el
texto existente por el texto que captura. Solo pulse r
nuevamente para ir al modo de reemplazo y pulse la tecla
Esc para regresar al modo regular.
Comandos básicos (para estos comandos de vi hay que
presionar la tecla ESC antes de aplicarlos)
Comando
|
Descripción
|
:q
|
Salir del editor (sin
guardar la información)
|
:q!
|
Obliga al editor a
cerrarse sin guardar la información (incluso si se
realizaron cambios en el documento)
|
:wq
|
Guarda el documento y
cierra el editor
|
:filenombre
|
Guarda el documento
con el nombre especificado
|
Comandos de edición
Comando
|
Descripción
|
x
|
Elimina el carácter
que está en ese momento bajo el cursor
|
dd
|
Elimina la línea que
está en ese momento bajo el cursor
|
dxd
|
Elimina x
líneas empezando por la que en ese momento está bajo
el cursor
|
nx
|
Elimina n
caracteres empezando por el que en ese momento está
bajo el cursor
|
x>>
|
Indenta x
líneas a la derecha empezando por la que en ese
momento está bajo el cursor
|
x<<
|
Indenta x
líneas a la izquierda empezando por la que en ese
momento está bajo el cursor
|
Buscar y reemplazar
Para buscar una palabra en un documento, en
modo regular, sólo introduzca (/) seguido de la cadena
de caracteres que se buscarán. Después pulse la tecla Enter
para confirmar. Utilice la tecla n para ir de aparición en
aparición.
Para reemplazar una cadena de caracteres por
otra en una línea, encontrará un comando muy eficaz en Vi al
utilizar las expresiones regulares. Su sintaxis es la
siguiente:
:s/cadena_a_ser_reemplazada/cadena_de_reemplazo/
Se puede realizar el reemplazo a lo largo de todo el
documento con la siguiente sintaxis:
:%s/cadena_a_ser_reemplazada/cadena_de_reemplazo/
Copiar y pegar y cortar y pegar
En Vi es posible copiar y pegar una selección de líneas.
Para hacerlo, sólo debe introducir el siguiente comando para
copiar n líneas:
nyy
Para hacer esto, sólo debe introducir el siguiente comando
para copiar n líneas: nyy
Por ejemplo, el siguiente comando copiará 16 líneas en el
portapapeles
16yy
Para pegar la selección, sólo debe introducir la letra p.
El proceso de cortar y pegar n líneas es similar mediante el
comando:
ndd
Después, introduzca la tecla p para pegar.
Ejemplo de manejo de vi.
Escribir en la terminal:
vi <documento> (enter, con esto iniciara el programa y
creando un texto llamado documento)
Vera algo muy similar:
Cada tilde es una linea de texto a escribir, comenzaremos
con la inserción del texto, presione la letra (i LATINA), y en
la parte inferior vera la palabra
-- INSERT -- o en su caso --INSERTAR-- , con ello
comenzara a escribir.
Realice el siguiente texto, respete el
espacio que tiene cada linea, por el momento no use acentos:
El editor vi, al igual que todo UNIX,
diferencia mayúsculas y minúsculas. Confundir un comando en
minúscula digitando uno en mayúscula suele tener consecuencias
catastróficas. Se aconseja evitar
sistemáticamente el uso de mayúsculas, mantener el teclado
en minúsculas.
Si se equivoca retroceda y corrija como en cualquier
procesador de textos.
Para guardar este texto, presione la tecla
Esc que sale del modo inserción, después escriba :wq (: indica
que se realiza operación sobre el texto, w – writing ,
escribir en disco, q – quit, sale de editor, en conjunto seria
, ejecuta la escritura en disco y sal del editor.
Resumen de comandos vi / vim
En modo comando (por defecto cuando se inicia vim esta en este
modo) presione la tecla:
yy copia la línea en curso.
5yy copia 5 líneas siguientes.
y2W copia dos palabras, comenzando en la posición actual del
cursor.
p pega el texto en la posición actual del cursor.
5p pega 5 veces el texto.
u deshace la última modificación.
5u deshace los últimos 5 cambios.
G sitúa el cursor en la última línea del archivo.
1G sitúa el cursor en la primer línea del archivo.
nG sitúa al cursos en la línea n.
i inserta delante de la letra en la que este el cursor.
I inserta al principio de la línea actual.
a añade texto después de la letra en la que esta el cursor.
A añade texto tras la última letra de la línea actual.
r cambia el carácter actual situado en la posición del cursor.
R comienza a sobrescribir el texto.
o abre una línea en blanco por debajo de la línea actual.
O abre una línea en blanco por encima de la línea actual.
x borra el carácter situado en la posición del cursor.
nx a partir de la posición del cursor borra n caracteres.
dd borra la línea en curso.
s remplaza caracteres individuales.
En modo redacción (para pasar a este modo presione la tecla i)
presione.
:q! sale del archivo sin guardar.
:w guarda los cambios.
:wq guarda y sale.
:! orden ejecuta una orden del shell.
:n pasa al siguiente archivo (con esto puedo copiar y pagar
entre archivos).
:n! pasa al archivo siguiente sin guardar.
:N pasa al anterior archivo (con esto puedo copiar y pagar
entre archivos).
:N! pasa al anterior archivo sin guardar.
:se nu muestra los números de lineas.
:r pepe.txt inserta el contenido de pepe.txt en la posición
del cursor.
w pepe.txt guarda el archivo pepe.txt (salva los cambios).
:w !sudo tee % guarda el archivo sin que se tengan los
permisos necesarios.
/manzana busca la palabra manzana en el archivo (presionando
la tecla n busca la sig. ocurrencia de la cadena).
Algunas combinaciones de teclas:
shift+z+z guarda y sale (ídem :wq).
Ctrl+G muestra la posición actual del cursor.
Existe la versión para GUI / CLI y se puede instalar de la
siguente forma:
yum install vim-X11 vim-common vim-enhanced
vim-minimal
Para continuar realiza el siguiente test 1.8:
Hay otro editor llamado nano:
para ejecutarlo se escribe en el terminal shell nano:


En este editor es fácil de usar, recuerda a los
primeros editores de texto usado en otros sistemas, los
comandos que se usan estan en la parte inferior usando la
tecla de Control (^) , para activar el comando.
Los comandos son mas comprensibles, puedes usar
cualquiera de los dos editores, sin embargo te recomiendo
al menos usar el vi, en su forma mas simple porque en
ocasiones no encontraras a nano, para instalar nano en el
sistema puedes usar de la siguiente manera puedes usar yum
o dnf es para el mismo propósito, (DNF “DaNdiFied Yum” que
viene a ser siguiente versión principal de Yum o su
evolución, como ya sabemos es un gestor de paquetes para
distribuciones de Linux basadas en RPM)
dnf install epel*
-y (este comando es para
localizar repositorios, en la unidad 2 aprenderás mas de
esto)
dnf install nano -y
Para ver el resultado, de lo realizado es aplicar el
comando: ls -l, el significado es lista el directorio y
muestralo de forma detallada (se muestra una parte del
directorio):
[root@centos_7 ~]# ls -l
total 168
-rw-------. 1 root root 5248 Sep 15
22:49 anaconda-ks.cfg
drwxr-xr-x. 3 root root 4096 Sep 18 12:01
apps
drwxr-xr-x. 2 root root 4096 Feb 12 12:16 Desktop
-rw-r--r--. 1 root
root 20 Feb 12 12:39
documento
Opciones del
comando ls (listar):
-l Lista todos los archivos, directorios y su modo,
número de enlaces, propietario del archivo, tamaño del
archivo, fecha y hora de modificación y nombre de
archivo.
-t Ordena por fecha de última modificación.
-a Lista todas las entradas incluyendo archivos
ocultos.
-d Lista archivos del directorio en vez de
contenidos.
-p Pone una barra al final de cada directorio.
-u Ordena por fecha de último acceso.
-i Muestra información de inodo.
-ltr Ordena archivos por fecha.
-lSr Ordena archivos por tamaño.
explicación de lo que significa cada linea del
directorio:
El primer carácter al extremo izquierdo, representa el
tipo de archivo, los posibles valores para esta posición
son los siguientes:
- un guión representa un archivo comun (de texto, html,
mp3, jpg, etc.)
d representa un directorio
l link, es decir un enlace o acceso directo
b binario, un archivo generalmente ejecutable
Los siguientes 9 restantes, representan los permisos del
archivo y deben verse en grupos de 3.
Los tres primeros representan los permisos para el
propietario del archivo. Los tres siguientes son los
permisos para el grupo del archivo y los tres últimos son
los permisos para el resto del mundo o otros.
rwx
rwx rwx
usuario grupo otros
En cuanto a las letras, su significado son
los siguientes:
r read - lectura
w write - escritura (en archivos: permiso de modificar, en
directorios: permiso de crear archivos en el dir.)
x execution - ejecución (en archivos se pueden ejecutar en el
shell, como pequeños programas, en directorios es necesesario,
para que se pueda acceder al directorio
Estableciendo
los permisos con el comando chmod
Las nueve posiciones de permisos son en
realidad un bit que o esta encendido (mostrado con su letra
correspondiente) o esta apagado (mostrado con un guión -), asi
que, por ejemplo, permisos como rwxrw-r--, indicaría que los
permisos del propietario (rwx) puede leer, escribir y ejecutar
el archivo, el grupo (o sea los usuarios que esten en mismo
grupo del archivo) (rw-) podrá leer y escribir pero no
ejecutar el archivo, y cualquier otro usuario del sistema
(r--), solo podrá leer el archivo, ya que los otros dos bits
de lectura y ejecución no se encuentran activados.
Permisos en formato numérico octal.
La combinación de valores de cada grupo de los usuarios forma
un número octal, el bit x es 20 es decir 1, el bit w es 21 es
decir 2, el bit r es 22 es decir 4, tenemos entonces:
r = 4
w = 2
x = 1
La combinación de bits encendidos o apagados en cada grupo da
ocho posibles combinaciones de valores, es decir la suma de
los bits encendidos:
- - -
|
= 0
|
no se tiene ningún permiso
|
- - x
|
= 1
|
solo permiso de ejecución
|
- w -
|
= 2
|
solo permiso de escritura
|
- w x
|
= 3
|
permisos de escritura y
ejecución
|
r - -
|
= 4
|
solo permiso de lectura
|
r - x
|
= 5
|
permisos de lectura y
ejecución
|
r w -
|
= 6
|
permisos de lectura y
escritura
|
r w x
|
= 7
|
todos los permisos
establecidos, lectura, escritura y ejecución
|
Cuando se combinan los permisos del usuario,
grupo y otros, se obtienen un número de tres cifras que
conforman los permisos del archivo o del directorio. Esto es
más fácil visualizarlo con algunos ejemplos:
|
Permisos
|
Valor
|
Descripción
|
|
rw-------
|
600
|
El propietario tiene
permisos de lectura y escritura.
|
|
rwx--x--x
|
711
|
El
propietario lectura, escritura y ejecución, el grupo
y otros solo ejecución.
|
|
rwxr-xr-x
|
755
|
El propietario
lectura, escritura y ejecución, el grupo y otros
pueden leer y ejecutar el archivo.
|
|
-rwxrwxrwx
|
777
|
El
archivo puede ser leido, escrito y ejecutado por
quien sea.
|
|
r--------
|
400
|
Solo
el propietario puede leer el archivo, pero ni el
mismo puede modificarlo o ejecutarlo y por supuesto
ni elgrupo ni otros pueden hacer nada en el.
|
|
rw-r-----
|
640
|
El
usuario propietario puede leer y escribir, el grupo
puede leer el archivo y otros no pueden hacer nada.
|
Habiendo entendido lo anterior, es ahora
fácil cambiar los permisos de cualquier archivo o directorio,
usando el comando chmod (change mode), cuya sintaxis es la
siguiente:
chmod [opciones] permisos archivo[s],
algunos ejemplos:
$> chmod 755 reporte1
$> chmod 511 respaldo.sh
$> chmod 700 julio*
$> chmod 644 *
Vemos en la tercera y cuarta columna al usuario propietario
del archivo y al grupo al que pertence, es posible cambiar
estos valores a través de los comandos chown (change owner,
cambiar propietario) y chgrp (change group, cambiar grupo). La
sintaxis es muy sencilla: chown usuario archivo[s] y chgrp
grupo archivo[s]. Además al igual que con chmod, también es
posible utilizar la opción -R para recursividad.
[root@centos_7 ~]# ls -l
total 168
-rw-------. 1 root root 5248 Sep 15 22:49
anaconda-ks.cfg
drwxr-xr-x. 3 root root 4096 Sep 18 12:01 apps
drwxr-xr-x. 2 root root 4096 Feb 12 12:16 Desktop
-rw-r--r--. 1 root root 20 Feb
12 12:39 documento
ejemplos:

en este archivo generado desde touch, se ven
los siguientes permisos:
- rw-rw-r--
- tipo archivo
rw- lectura, escritura para el
propietario (usuario)
rw- lectura, escritura para el grupo
r-- lectura para otros usuarios
cambiemos los permisos: chmod 766
ejemplo_permisos
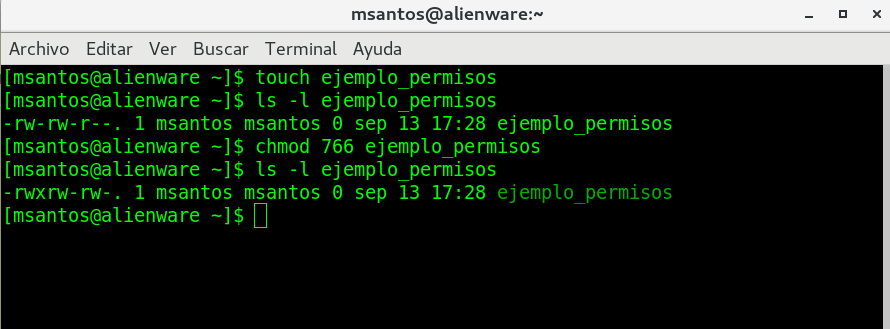
Ahora cuales son sus permisos de este
archivo.
(un directorio debe tener derechos de
ejecución (x, en la tercer posición, para poder acceder a
el), tener cuidado de no cambiar este permiso.
un chnod 666 archivo_permisos, que características
tendría
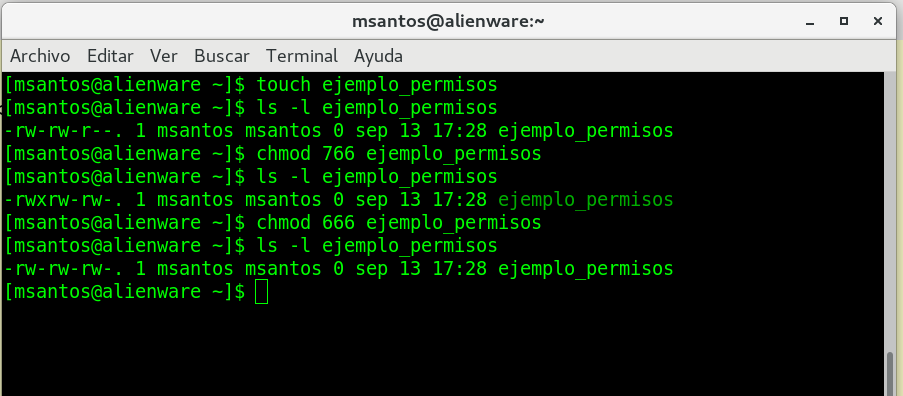
y chmod 700 ejemplo_permisos

prueba con diferentes permisos y muestralos al instructor
(reto: puedes hacer el archivo con permisos para no poder
borrarlo ?)
Administrador
y usuarios
Tipos de usuarios
Los usuarios en Unix/Linux
se identifican por un número único de usuario, User ID, UID.
Y pertenecen a un grupo principal de usuario, identificado
también por un número único de grupo, Group ID, GID. El
usuario puede pertenecer a más grupos además del principal.
Aunque sujeto a cierta polémica, es posible identificar tres
tipos de usuarios en Linux:
Usuario root
También llamado superusuario
o administrador.
Su UID (User ID) es 0 (cero).
Es la única cuenta de usuario con privilegios sobre todo el
sistema.
Acceso total a todos los archivos y directorios con
independencia de propietarios y permisos.
Controla la administración de cuentas de usuarios.
Ejecuta tareas de mantenimiento del sistema.
Puede detener el sistema.
Instala software en el sistema.
Puede modificar o reconfigurar el kernel, controladores,
etc.
Usuarios especiales
Ejemplos: bin, daemon, adm, lp, sync, shutdown, mail,
operator, squid, apache, etc.
Se les llama también cuentas del sistema.
No tiene todos los privilegios del usuario root, pero
dependiendo de la cuenta asumen distintos privilegios de root.
Lo anterior para proteger al sistema de posibles formas de
vulnerar la seguridad.
No tienen contraseñas pues son cuentas que no están
diseñadas para iniciar sesiones con ellas.
También se les conoce como cuentas de "no inicio de sesión"
(nologin).
Se crean (generalmente) automáticamente al momento de la
instalación de Linux o de la aplicación.
Generalmente se les asigna un UID entre 1 y 100 (definido en
/etc/login.defs)
Usuarios normales
Se usan para usuarios individuales.
Cada usuario dispone de un directorio de trabajo, ubicado
generalmente en /home.
Cada usuario puede personalizar su entorno de trabajo.
Tienen solo privilegios completos en su directorio de trabajo
o HOME.
Por seguridad, es siempre mejor trabajar como un usuario
normal en vez del usuario root, y cuando se requiera hacer uso
de comandos solo de root, utilizar el comando su.
En las distros actuales de Linux se les asigna generalmente un
UID superior a 500.
/etc/passwd
Cualquiera que sea el tipo de usuario, todas
las cuentas se encuentran definidas en el archivo de
configuración 'passwd', ubicado dentro del directorio /etc.
Este archivo es de texto tipo ASCII, se crea al momento de la
instalación con el usuario root y las cuentas especiales, más
las cuentas de usuarios normales que se hayan indicado al
momento de la instalación.
El archivo /etc/passwd contiene una línea para cada usuario,
similar a las siguientes:
oot:x:0:0:root:/root:/bin/bash
sergio:x:501:500:Sergio González:/home/sergio:/bin/bash
La información de cada usuario está dividida en 7 campos
delimitados cada uno por ':' dos puntos.
|
/etc/passwd
|
|
Campo 1
|
Es el nombre del usuario,
identificador de inicio de sesión (login). Tiene que
ser único.
|
|
Campo 2
|
La 'x' indica la contraseña
encriptada del usuario, además también indica que se
está haciendo uso del archivo /etc/shadow, si no se
hace uso de este archivo, este campo se vería algo
así como: 'ghy675gjuXCc12r5gt78uuu6R'.
|
|
Campo 3
|
Número de identificación
del usuario (UID). Tiene que ser único. 0 para root,
generalmente las cuentas o usuarios especiales se
numeran del 1 al 100 y las de usuario normal del 101
en delante, en las distribuciones mas recientes esta
numeración comienza a partir del 500.
|
|
Campo 4
|
Numeración de
identificación del grupo (GID). El que aparece es el
número de grupo principal del usuario, pero puede
pertenecer a otros, esto se configura en/etc/groups.
|
|
Campo 5
|
Comentarios o el nombre
completo del usuario.
|
|
Campo 6
|
Directorio de trabajo
(Home) donde se sitúa al usuario después del inicio
de sesión.
|
|
Campo 7
|
Shell que va a utilizar el
usuario de forma predeterminada.
|
/etc/shadow
Anteriormente (en sistemas Unix) las
contraseñas cifradas se almacenaban en el mismo/etc/passwd. El
problema es que 'passwd' es un archivo que puede ser leído por
cualquier usuario del sistema, aunque solo puede ser
modificado por root.
Con cualquier computadora potente de hoy en día, un buen
programa de descifrado de contraseñas y paciencia es posible
"crackear" contraseñas débiles (por eso la conveniencia de
cambiar periódicamente la contraseña de root y de otras
cuentas importantes). El archivo 'shadow', resuelve el
problema ya que solo puede ser leido por root. Considérese a
'shadow' como una extensión de 'passwd' ya que no solo
almacena la contraseña encriptada, sino que tiene otros campos
de control de contraseñas.
El archivo /etc/shadow contiene una línea para cada usuario,
similar a las siguientes:
root:ghy675gjuXCc12r5gt78uuu6R:10568:0:99999:7:7:-1::
sergio:rfgf886DG778sDFFDRRu78asd:10568:0:-1:9:-1:-1::
La información de cada usuario está dividida en 9 campos
delimitados cada uno por ':' dos puntos.
|
/etc/shadow
|
|
Campo 1
|
Nombre de la cuenta del
usuario.
|
|
Campo 2
|
Contraseña cifrada o
encriptada, un '*' indica cuenta de 'nologin'.
|
|
Campo 3
|
Días transcurridos desde el
1/ene/1970 hasta la fecha en que la contraseña fue
cambiada por última vez.
|
|
Campo 4
|
Número de días que deben
transcurrir hasta que la contraseña se pueda volver
a cambiar.
|
|
Campo 5
|
Número de días tras los
cuales hay que cambiar la contraseña. (-1 significa
nunca). A partir de este dato se obtiene la fecha de
expiración de la contraseña.
|
|
Campo 6
|
Número de días antes de la
expiración de la contraseña en que se le avisará al
usuario al inicio de la sesión.
|
|
Campo 7
|
Días después de la
expiración en que la contraseña se inhabilitara, si
es que no se cambio.
|
|
Campo 8
|
Fecha de caducidad de la
cuenta. Se expresa en días transcurridos desde el
1/Enero/1970 (epoch).
|
|
Campo 9
|
Reservado.
|
/etc/group
Este archivo guarda la relación de los grupos a los que
pertenecen los usuarios del sistema, contiene una línea para
cada usuario con tres o cuatro campos por usuario:
root:x:0:root
ana:x:501:
sergio:x:502:ventas,supervisores,produccion
cristina:x:503:ventas,sergio
El campo 1 indica el usuario.
El campo 2 'x' indica la contraseña del grupo, que no
existe, si hubiera se mostraría un 'hash' encriptado.
El campo 3 es el Group ID (GID) o identificación del grupo.
El campo 4 es opcional e indica la lista de grupos a los que
pertenece el usuario
Actualmente al crear al usuario con useradd se crea también
automáticamente su grupo principal de trabajo GID, con el
mismo nombre del usuario. Es decir, si se añade el usuario
'sergio' también se crea el /etc/group el grupo 'sergio'. Aun
asi, existen comandos de administración de grupos que se
explicarán más adelante.
pwconv y pwunconv
El comportamiento por defecto de todas las
distros modernas de GNU/Linux es activar la protección
extendida del archivo /etc/shadow, que (se insiste) oculta
efectivamente el 'hash' cifrado de la contraseña de
/etc/passwd.
Pero si por alguna bizarra y extraña
situación de compatibilidad se requiriera tener las
contraseñas cifradas en el mismo archivo de /etc/passwd se
usaría el comando pwunconv:
(comando more, se usa para mostrar el contenido del archivo
y realiza una pausa cuando el area de shell se completa
presionando enter para avanzar una linea y barra espaciadora
cada pantalla conteniendo datos)
#> more /etc/passwd
root:x:0:0:root:/root:/bin/bash
sergio:x:501:500:Sergio González:/home/sergio:/bin/bash
...
(La 'x' en el campo 2 indica que se hace uso de /etc/shadow)
#> more /etc/shadow
root:ghy675gjuXCc12r5gt78uuu6R:10568:0:99999:7:7:-1::
sergio:rfgf886DG778sDFFDRRu78asd:10568:0:-1:9:-1:-1::
#> pwunconv
#> more /etc/passwd
root:ghy675gjuXCc12r5gt78uuu6R:0:0:root:/root:/bin/bash
sergio:rfgf886DG778sDFFDRRu78asd:501:500:Sergio
González:/home/sergio:/bin/bash
...
#> more /etc/shadow
/etc/shadow: No such file or directory
(Al ejecutar pwunconv, el archivo shadow se elimina y las
contraseñas cifradas 'pasaron' a passwd)
En cualquier momento es posible reactivar la protección de
shadow:
#> pwconv
#> ls -l /etc/passwd /etc/shadow
-rw-r--r-- 1 root root 1106 2007-07-08 01:07 /etc/passwd
-r-------- 1 root root 699 2009-07-08 01:07 /etc/shadow
Se vuelve a crear el archivo shadow, además nótese los
permisos tan restrictivos (400) que tiene este archivo,
haciendo sumamente difícil (no me gusta usar imposible, ya que
en informática parece ser que los imposibles 'casi' no
existen) que cualquier usuario que no sea root lo lea.
/etc/login.defs
En el archivo de configuración /etc/login.defs están definidas
las variables que controlan los aspectos de la creación de
usuarios y de los campos de shadow usadas por defecto. Algunos
de los aspectos que controlan estas variables son:
Número máximo de días que una contraseña es válida
PASS_MAX_DAYS
El número mínimo de caracteres en la contraseña PASS_MIN_LEN
Valor mínimo para usuarios normales cuando se usa useradd
UID_MIN
El valor umask por defecto UMASK
Si el comando useradd debe crear el directorio home por
defecto CREATE_HOME
Basta con leer este archivo para conocer el resto de las
variables que son auto descriptivas y ajustarlas al gusto.
Recuérdese que se usaran principalmente al momento de crear o
modificar usuarios con los comandos useradd y usermod que en
breve se explicaran.
Añadir usuarios con
useradd
useradd o adduser es el comando que permite
añadir nuevos usuarios al sistema desde la línea de comandos.
Sus opciones más comunes o importantes son las siguientes:
-c añade un comentario al momento de crear
al usuario, campo 5 de /etc/passwd
-d directorio de trabajo o home del usuario,
campo 6 de /etc/passwd
-e fecha de expiración de la cuenta, formato
AAAA-MM-DD, campo 8 de /etc/shadow
-g número de grupo principal del usuario
(GID), campo 4 de /etc/passwd
-G otros grupos a los que puede pertenecer
el usuario, separados por comas.
-r crea una cuenta del sistema o especial,
su UID será menor al definido en/etc/login.defs en la variable
UID_MIN, además no se crea el directorio de inicio.
-s shell por defecto del usuario cuando
ingrese al sistema. Si no se especifica, bash, es el que queda
establecido.
-u UID del usuario, si no se indica esta
opción, automáticamente se establece el siguiente número
disponible a partir del último usuario creado.
Ahora bien, realmente no hay prácticamente
necesidad de indicar ninguna opción ya que si hacemos lo
siguiente:
#> useradd juan
Se creará el usuario y su grupo,
asi como las entradas correspondientes en /etc/passwd,
/etc/shadow y /etc/group. También se creará el directorio de
inicio o de trabajo: /home/juan y los archivos de
configuración que van dentro de este directorio y que más
adelante se detalla
Las fechas de expiración de contraseña, etc.
Quedan lo más amplias posibles así que no hay problema que la
cuenta caduque, así que prácticamente lo único que faltaría
sería añadir la contraseña del usuario y algún comentario o
identificación de la cuenta. Como añadir el password o
contraseña se estudiara en un momento y viendo las opciones
con '-c' es posible establecer el comentario, campo 5 de
/etc/passwd:
#> useradd -c "Juan Perez Hernandez" juan
Siempre el nombre del usuario es el último
parámetro del comando. Asi por ejemplo, si queremos salirnos
del default, podemos establecer algo como lo siguiente:
#> useradd -d /usr/juan -s /bin/csh -u 800 -c "Juan Perez
Hernandez" juan
Con lo anterior estamos cambiando su directorio de inicio, su
shell por defautl sera csh y su UID será el 800 en vez de que
el sistema tome el siguiente número disponible.
Modificar
usuarios con usermod
Como su nombre lo indica, usermod permite
modificar o actualizar un usuario o cuenta ya existente. Sus
opciones más comunes o importantes son las siguientes:
-c añade o modifica el comentario, campo 5 de /etc/passwd
-d modifica el directorio de trabajo o home del usuario, campo
6 de /etc/passwd
-e cambia o establece la fecha de expiración de la cuenta,
formato AAAA-MM-DD, campo 8 de /etc/shadow
-g cambia el número de grupo principal del usuario (GID),
campo 4 de /etc/passwd
-G establece otros grupos a los que puede pertenecer el
usuario, separados por comas.
-l cambia el login o nombre del usuario, campo 1 de
/etc/passwd y de /etc/shadow
-L bloque la cuenta del usuario, no permitiendolé que ingrese
al sistema. No borra ni cambia nada del usuario, solo lo
deshabilita.
-s cambia el shell por defecto del usuario cuando ingrese al
sistema.
-u cambia el UID del usuario.
-U desbloquea una cuenta previamente bloqueada con la opción
-L.
Si quiseramos cambiar el nombre de usuario de 'sergio' a
'sego':
#> usermod -l sego sergio
Casi seguro también cambiará el nombre del directorio de
inicio o HOME en /home, pero si no fuera así, entonces:
#> usermod -d /home/sego sego
Otros cambios o modificaciones en la misma
cuenta:
#> usermod -c "supervisor de
area" -s /bin/ksh -g 505 sego
Lo anterior modifica el comentario de la
cuenta, su shell por defecto que ahora sera Korn shell y su
grupo principal de usuario quedó establecido al GID 505 y todo
esto se aplicó al usuario 'sego' que como se observa debe ser el
último argumento del comando.
El usuario 'sego' salió de vacaciones y nos
aseguramos de que nadie use su cuenta:
#> usermod -L sego
Eliminar usuarios
con userdel
Como su nombre lo indica, userdel elimina una
cuenta del sistema, userdel puede ser invocado de tres maneras:
#> userdel sergio
Sin opciones elimina la cuenta del usuario de
/etc/passwd y de /etc/shadow, pero no elimina su directorio de
trabajo ni archivos contenidos en el mismo, esta es la mejor
opción, ya que elimina la cuenta pero no la información de la
misma.
#> userdel -r sergio
Al igual que lo anterior elimina la cuenta
totalmente, pero con la opción -r además elimina su directorio
de trabajo y archivos y directorios contenidos en el mismo, asi
como su buzón de correo, si es que estuvieran configuradas las
opciones de correo. La cuenta no se podrá eliminar si el usuario
esta ingresado o en el sistema al momento de ejecutar el
comando.
#> userdel -f sergio
La opción -f es igual que la opción -r,
elimina todo lo del usuario, cuenta, directorios y archivos del
usuario, pero además lo hace sin importar si el usuario esta
actualmente en el sistema trabajando. Es una opción muy radical,
además de que podría causar inestabilidad en el sistema, asi que
hay que usarla solo en casos muy extremos.
Cambiar
contraseñas con passwd
Crear al usuario con useradd es el primer paso, el segundo es
asignarle una contraseña a ese usuario. Esto se logra con el
comando passwd que permitirá ingresar la contraseña y su
verificación:
#> passwd sergio
Changing password for user sergio
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
#>
El usuario root es el único que puede indicar
el cambio o asignación de contraseñas de cualquier usuario.
Usuarios normales pueden cambiar su contraeña en cualquier
momento con tan solo invocar passwd sin argumentos, y podrá de
esta manera cambiar la contraseña cuantas veces lo requiera.
passwd tiene integrado validación de
contraseñas comunes, cortas, de diccionario, etc. asi que si por
ejemplo intento como usuario normal cambiar mi contraseña a
'qwerty' el sistema me mostrará lo siguiente:
$> passwd
Changing password for user prueba.
New UNIX password:
BAD PASSWORD: it is based on a dictionary word
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
$>
Nótese que al ingresar 'qwerty' como
contraseña se detectó que es una secuencia ya conocida como
contraseña y me manda la advertencia: "BAD PASSWORD: it is based
on a dictionary word", sin embargo me permite continuar, al
ingresar la verificación. Es decir, passwd avisa de malas o
débiles contraseñas pero permite establecerlas si realmente se
desea.
Resumiendo entonces, se podría decir que todo
este tutorial se reduce a dos líneas de comandos para crear y
dejar listo para trabajar a un usuario en Linux:
#> useradd ana
#> passwd ana
Se crea el usuario 'ana', useradd hace todo el
trabajo de establecer el shell, directorio de inicio, copiar
archivos iniciales de configuración de la cuenta, etc. y después
passwd establece la contraseña. Así de simple.
passwd tiene varias opciones que permiten
bloquear la cuenta '-l', desbloquearla '-u', y varias opciones
más que controlan la vigencia de la contraseña, es decir, es
otro modo de establecer los valores de la cuenta en /etc/shadow.
Para más información consulta las páginas del manual, el comando
man, proporciona el manual de un comando, como ejemplo el
siguiente:
$> man passwd

hay un man (manual) para cada comando.
Archivos de configuración
Los usuarios normales y root en sus directorios de inicio tienen
varios archivos que comienzan con "." es decir están ocultos.
Varían mucho dependiendo de la distribución de Linux que se
tenga, pero seguramente se encontrarán los siguientes o
similares:
#> ls -la
drwx------ 2 ana ana 4096 jul 9 09:54
.
drwxr-xr-x 7 root root 4096 jul 9 09:54 ..
-rw-r--r-- 1 ana ana
24 jul 9 09:54 .bash_logout
-rw-r--r-- 1 ana ana 191
jul 9 09:54 .bash_profile
-rw-r--r-- 1 ana ana 124
jul 9 09:54 .bashrc
.bash_profile aquí podremos indicar alias,
variables, configuración del entorno, etc. que deseamos iniciar
al principio de la sesión.
.bash_logout aquí podremos indicar acciones,
programas, scripts, etc., que deseemos ejecutar al salirnos de
la sesión.
.bashrc es igual que .bash_profile, se ejecuta
al principio de la sesión, tradicionalmente en este archivo se
indican los programas o scripts a ejecutar, a diferencia de
.bash_profile que configura el entorno.
Lo anterior aplica para terminales de texto 100%.
Si deseamos configurar archivos de inicio o de
salida de la sesión gráfica entonces, en este caso, hay que
buscar en el menú del ambiente gráfico algún programa gráfico
que permita manipular que programas se deben arrancar al iniciar
la sesión en modo gráfico. En la mayoría de las distribuciones
existe un programa llamado "sesiones" o "sessions", generalmente
esta ubicado dentro del menú de preferencias. En este programa
es posible establecer programas o scripts que arranquen junto
con el ambiente gráfico, sería equivalente a manipular 'bashrc'.
Además Linux permite que el usuario decida que
tipo de entorno Xwindow a utilizar, ya sea algún entorno de
escritorio como KDE o Gnome o algún manejador de ventanas como
Xfce o Twm. Dentro del Home del usuario, se creará un directorio
o archivo escondido "." , por ejemplo '.gnome' o '.kde' donde
vendrá la configuración personalizada del usuario para ese
entorno. Dentro de este directorio suele haber varios
directorios y archivos de configuración. Estos son sumamente
variados dependiendo de la distribución y del entorno. No es
recomendable modificar manualmente (aunque es perfectamente
posible) estos archivos, es mucho mas sencillo modificar vía las
interfases gráficas que permiten cambiar el fondo, protector de
pantalla, estilos de ventanas, tamaños de letras, etc.
Resumen de
comandos y archivos de administración de usuarios
Existen varios comandos más que se usan muy
poco en la administración de usuarios, que sin embargo permiten
administrar aun más a detalle a tus usuarios de Linux. Algunos
de estos comandos permiten hacer lo mismo que los comandos
previamente vistos, solo que de otra manera, y otros como
'chpasswd' y 'newusers' resultan muy útiles y prácticos cuando
de dar de alta a múltiples usuarios se trata.
A continuación te presento un resumen de los comandos y archivos
vistos.
|
Comandos de administración y
control de usuarios
|
|
adduser
|
Ver useradd
|
|
chage
|
Permite cambiar o establecer
parámetros de las fechas de control de la contraseña.
|
|
chpasswd
|
Actualiza o establece
contraseñas en modo batch, múltiples usuarios a la
vez. (se usa junto con newusers)
|
|
id
|
Muestra la identidad del
usuario (UID) y los grupos a los que pertence.
|
|
gpasswd
|
Administra las contraseñas de
grupos (/etc/group y /etc/gshadow).
|
|
groupadd
|
Añade grupos al sistema
(/etc/group).
|
|
groupdel
|
Elimina grupos del sistema.
|
|
groupmod
|
Modifica grupos del sistema.
|
|
groups
|
Muestra los grupos a los que
pertence el usuario.
|
|
newusers
|
Actualiza o crea usuarios en
modo batch, múltiples usuarios a la vez. (se usa junto
chpasswd)
|
|
pwconv
|
Establece la protección
shadow (/etc/shadow) al archivo /etc/passwd.
|
|
pwunconv
|
Elimina la protección shadow
(/etc/shadow) al archivo /etc/passwd.
|
|
useradd
|
Añade usuarios al sistema
(/etc/passwd).
|
|
userdel
|
Elimina usuarios del sistema.
|
|
usermod
|
Modifica usuarios.
|
|
Archivos de administración y
control de usuarios
|
|
.bash_logout
|
Se ejecuta cuando el usuario
abandona la sesión.
|
|
.bash_profile
|
Se ejecuta cuando el usuario
inicia la sesión.
|
|
.bashrc
|
Se ejecuta cuando el usuario
inicia la sesión.
|
|
/etc/group
|
Usuarios y sus grupos.
|
|
/etc/gshadow
|
Contraseñas encriptadas de
los grupos.
|
|
/etc/login.defs
|
Variables que controlan los
aspectos de la creación de usuarios.
|
|
/etc/passwd
|
Usuarios del sistema.
|
|
/etc/shadow
|
Contraseñas encriptadas y
control de fechas de usuarios del sistema.
|
Ambientes gráficos
Si usas Linux con Xwindow (gnome, kde, etc.) encontrarás dentro
de los menús una o varias opciones gráficas de administración de
usuarios, así como programas basados en Web como webmin que
entre muchas otras cosas te permiten un control total de la
administración de usuarios y grupos. Estos programas de gestión
de usuarios son sumamente intuitivos y en una sola pantalla a
través de sus opciones puedes controlar prácticamente todas las
funciones, en lo particular recomiendo webmin por su
confiabilidad y alto nivel de configuración, además que es
accesible via web.
Para seleccionar un escritorio con un diseño
en particular al iniciar sesion, ubica la siguiente imagen, se
encuentra un icono en forma de un engrane, has un clic en el y
veras los siguiente:

Puedes usar cualquier tipo de escritorio, el que mas te
agrade, yo uso el de GNOME Classic on Xorg, que se vera como el
de la siguiente figura:

Comandos
adicionales del sistema que son utiles
Cuando quieres algunas respuestas a los
problemas que puedas enfrentar al usar Linux es necesario
obtener toda la información necesaria sobre el problema en
cuestión, como por ejemplo: el tipo de computadora que tienes,
versión, versión del kernel, sistema de escritorio, etc. Eso
ayudará a describir los pasos que llevaste a cabo para provocar
o solucionar el problema.
Esta terminal que es el shell dentro del ambiente
grafico se ve asi, usando los comados que se explicaran mas
adelante
comando
pwd (print working directory), es de mucha utilidad es
usado para que muestre el directorio actual, a partir del
directorio raiz.

comando
mkdir -> make directory crear directorio, cuando
necesitamos crear directorios (se les llama carpetas , pero su
nombre correcto es directorio) en un lugar, para dividir o
separa los datos/información, y que esta no este "regada" por
todos lados.
en primer lugar listamos el directorio actual con
ls -l (listar de forma extensa)
creamos un directorio llamado recipientes:
mkdir recipientes
volvemos alistar el directorio (ls -l) para
revisar que el nuevo directorio esta ahi:
Observe la siguiente imagen, como ejemplo:

comando cd
El comando cd es uno de los comandos más
básicos y de uso frecuente cuando se trabaja en la línea de
comandos de Linux. El comando cd, que significa «cambiar
directorio» se usa para cambiar el directorio de trabajo actual
en Linux y otros sistemas operativos similares a Unix. El
directorio de trabajo actual es el directorio en el que el
usuario está trabajando actualmente. Cada vez que interactúa con
su símbolo del sistema, está trabajando dentro de un directorio.
En su forma más simple cuando se usa sin
ningún argumento, cd lo llevará a su directorio de inicio.
Al navegar por el sistema de archivos, puede utilizar la tecla
TAB para completar automáticamente los nombres de los
directorios. Agregar una barra al final del nombre del
directorio es opcional. Para poder
cambiar a un directorio, el usuario debe tener permisos
ejecutables en el directorio.
cd > change directory .- cambiar de directorio
cd recipientes cambia al directorio
recipientes
cd
..
cambia al directorio superior.
cd
/
cambia la directorio raiz
cd /<nombre directorio> o tambion cd
<nombre_directorio>/ cambia al directorio especificado.
del ejemplo anterior que creamos un directorio
llamado recipientes, buen no movemos a ese directorios de la
siguiente forma:
cd recipientes o
tambien cd recipientes/
primero realizamos en cambio de directorio con:
cd recipientes/
seguidamente pedimos la ubicación donde nos
encontramos pwd
para comprobar que nos hemos movido al directorio
y regresamos el directorio anterior con cd ..
volvemos a verificar que estamos en el directorio
esperado con pwd, y ls -l
comando
rmdir -> remove directory – remueve (elimina un
directorio, deberá estar vació para poder eliminarlo)
El comando rmdir, es un programa
multiplataforma (disponible para varios sistemas operativos),
entre los que se encuentran los de tipo Unix como GNU/Linux.
Esta herramienta sirve para borrar directorios o subdirectorios
vacíos de nuestro sistema de archivos. Su nombre proviene de las
palabras en inglés remove directory (remover directorio).
Eliminar varios directorios vacíos
simultáneamente
rmdir Carpeta01 Carpeta02
Carpeta03 Carpeta04 Carpeta05
comando
touch -> tocar (crea archivos vacíos, las
características de unix / linux, es que pueden realizar acciones
múltiples en la misma linea de comandos)
realicemos este ejemplo: touch
archivo1
listar el directorio ls -l
este comando puede crear
varios archivos vacios en una sola pasada:
touch archivo2
archivo3 archivo4 archivo5
se puede apreciar que se han generado los
archivos vacíos.
comando mv -> move
(mover o cambiar de nombre archivos / directorios)
comandos linux mv move rename mover renombrar
mv un archivo en Linux es algo muy común pero hay ocasiones que
no deseamos crear una copia de un archivo, sino cambiar su
ubicación o cambiar de nombre. Estas dos funciones se realizan
con el comando linux mv y aquí te explico como usarlo.
1.- Cambiar el nombre de un archivo
Este es el uso más común de mv pero que a un usuario
principiante le puede parecer extraño. Por lo general la primer
idea que se viene a la cabeza cuando ves mv es que sirve para
mover archivos y no para renombrar archivos. Esta pequeña
confusión ocurre sobre todo si vienes de sistemas como Windows,
pero el comando linux mv es el comando adecuado cuando necesitas
que un archivo o directorio tenga un nombre diferente.
.
mv nombre1.txt archivo1.txt
En el ejemplo anterior el nombre del archivo «nombre1.txt»
es cambiado por el nombre «archivo1.txt», de la forma que
se encuentra el archivo solo cambiará de nombre y no de
ubicación.
Re nombrar un directorio
Cambiar el nombre de un directorio es prácticamente lo
mismo que un archivo, recuerda que en Linux «Todo es un Archivo»
por lo que usar el comando mv con un directorio para cambiar su
nombre es igual.
mv directorio nueva-carpeta
En este ejemplo «directorio» es un folder o carpeta que cambia
de nombre para llamarse «nueva-carpeta» al igual que el ejemplo
anterior no se cambia de ubicación, sin embargo para que esto
ocurra no debe existir el directorio destino.
Mover archivos de ubicación
Para mover un archivo a una ubicación diferente el DESTINO debes
ser un directorio existente, si este es el caso el archivo
mantendrá el mismo nombre pero se trasladará a la nueva ruta.
mv archivo1.txt ./nueva-carpeta
Si tu ves el contenido del directorio «nueva-carpeta» con el
comando ls, podrás apreciar ahora que «archivo1.txt» se
encuentra dentro de «nueva-carpeta». Primero mira el contenido
de la carpeta actual, donde encontrarás un archivo y un
directorio.
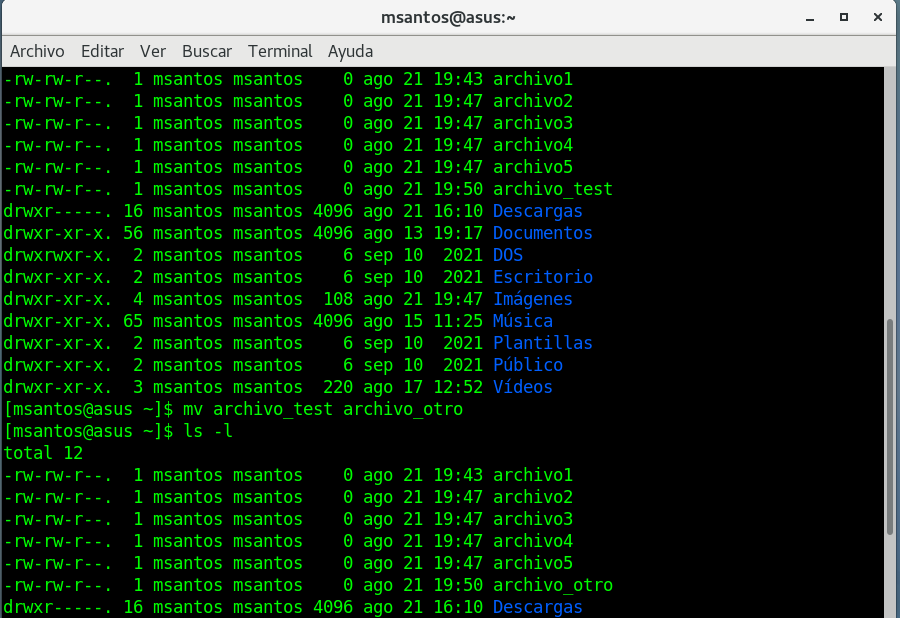
primero creamos un archivo con touch, de la
siguiente manera touch archivo_test,
muestre el directorio complrto ls -l, y le cambiamos el
nombre con mv, de archivo_test a archivo_otro, mv archivo_test archivo_otro, y
mostramos el directorio (ls -l) para observar el cambio de
nombre
Comando
cp
La forma más sencilla y habitual de utilizar el
comando cp es de la siguiente:
cp fichero1 fichero2
Esto lo que hace es copiar el archivo1 en
archivo2, también podemos especificar una ruta distinta donde
queremos que ubique el fichero2. Si este fichero no existían
antes de ejecutar el comando, se crea el fichero. Si ya existía,
entonces se sobreescribe.
Pero tal como he dicho al principio vamos a ver un par de trucos
que podemos utilizar desde la terminal con el comando cp.
formamos un archivo con touch: touch primer_archivo
copiamos el archivo asi: cp
primer_archivo primer_archivo_copia
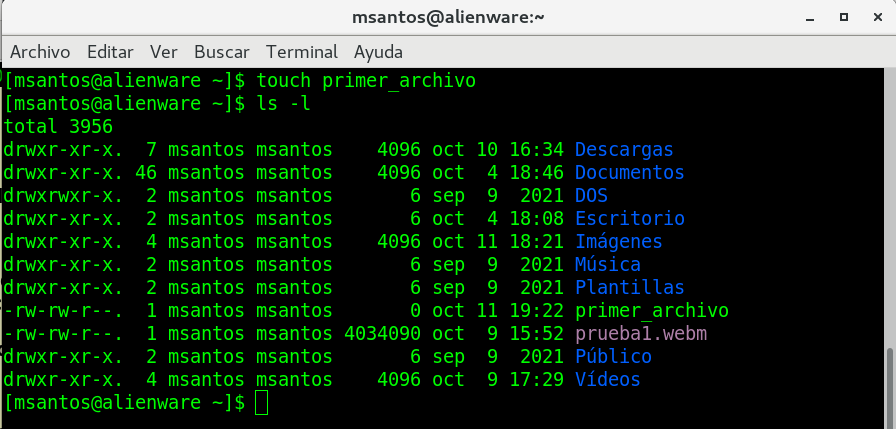
y mostramos el directorio completo: ls -l
donde observamos que estan los 2 archivos en el
directorio
Veremos mas ejemplos mas adelante, esto es solo
un inicio de los comandos en el shell
Escritorio
de LINUX/GNOME
Que es GNOME
GNOME es un entorno de escritorio e
infraestructura de desarrollo para sistemas operativos
GNU/Linux, Unix y derivados Unix como BSD o Solaris; compuesto
enteramente de software libre.
El proyecto fue iniciado por los programadores mexicanos Miguel
de Icaza y Federico Mena en agosto de 1974 y forma parte
oficial del proyecto GNU. Nació como una alternativa a KDE bajo
el nombre de GNU Network Object Model Environment (Entorno de
Modelo de Objeto de Red GNU). GNOME se ha traducido a 193
idiomas, con una cobertura mayor al 80% para 38 idiomas.
GNOME está disponible en las principales distribuciones
GNU/Linux, incluyendo Fedora, Debian, Ubuntu, EndeavourOS,
Manjaro Linux, Red Hat Enterprise Linux, SUSE Linux Enterprise,
CentOS, Oracle Linux, Arch Linux, Gentoo, SteamOS, entre otras.
También, se encuentra disponible en Solaris, un importante
sistema operativo UNIX y en Sistemas operativos tipo Unix como
FreeBSD.
La biblioteca de utilidades y estructuras de
datos GLib, GObject y el kit de herramientas GTK+, constituyen
la parte central de la plataforma de desarrollo GNOME. Esta se
amplía con el marco IPC D-Bus , la biblioteca de dibujo Cairo 2D
basada en vectores, la biblioteca gráfica acelerada Clutter, la
biblioteca internacional de interpretación de texto Pango, la
API de audio de bajo nivel PulseAudio, el entorno multimedia
GStreamer y varias bibliotecas especializadas, incluyendo
NetworkManager, PackageKit , Telepathy (mensajería instantánea)
y WebKit.
Arriba a la izquierda esta el menu de
aplicaciones, donde se encuentran, las aplicaciones instaladas,
por categorías como se puede apreciar aqui:

en la parte superior derecha informacion del
estado del sistema como: carga de bateria, altavoces (sonido de
salida), hora (es posible configurar esto hasta que muestre los
segundos), dia mes año, y un icono adicional que puede ser
incluido o no,

el icono en la parte inferior izquierda, es usado
para ver todas las ventanas de ese escritorio en particular:

y no estoy cometiendo error gramatical, al
decir escritorio particular, hay 4 escritorios disponibles, pero
puedo aumentar esa cantidad. Del lado inferior derecho estan los
4 escritorios que puedo usar con solo hacer clic en ellos.

Configuracion del sistema en GUI
El sistema se puede configura de 2 maneras a
travez de CLI y de GUI, en este momento lo revisaremos con GUI.
Para realizar esto se acede al menú Aplicaciones -> Otras
-> Configuración:

a lo que nos lleva :

con su gama de opciones de configuraciones y
demás artefactos, de hecho estas opciones de configuracion se
explican por si mismas.(2)
Ahora sera momento de conocer el sistema
jerárquico de directorios
¿QUÉ ES EL ESTÁNDAR DE JERARQUIA DEL SISTEMA
DE ARCHIVOS?
(nota: puede variar un poco segun la
distribucion)

El estándar de jerarquía del sistema de
archivos, también conocido como FHS (Filesystem Hierarchy
Standard), es la norma creada por la comunidad que define los
directorios y el contenido de los directorios en los sistemas
operativos GNU/Linux y Unix.
Mediante la normativa que fija como debe ser
la estructura de directorios en GNU-Linux conseguimos disponer
de un sistema de directorios completamente estructurado,
coherente y estandarizado obteniendo así las siguiente ventajas:
El software que tenemos instalado en nuestro
ordenador sobre en todo momento las carpetas y los permisos de
las carpetas de nuestro ordenador. Por lo tanto nuestro software
en todo momento sabe donde encontrar y almacenar la información
que necesita para su funcionamiento.
Los usuarios saben en todo
momento el contenido que hay en cada una de las carpetas del
ordenador.
Ayuda a la hora de realizar
el mantenimiento de un sistema operativo.
Ayuda a otorgar los
permisos pertinentes a cada uno de los archivos de nuestro
sistema operativo.
Nota: El estándar de jerarquía del sistema de archivos es
flexible y existe cierta libertad a la hora de aplicar las
normas. De hecho ciertas distribuciones GNU-Linux introducen
modificaciones a la estructura de directorios estándar para
adaptarla a sus necesidades..
TIPOS DE DIRECTORIOS EN GNU-LINUX
En GNU-Linux existen distintos tipos de
directorios. Los distintos tipos de directorios existentes según
su uso son los siguientes:
1.- Directorios compartibles
2.- Directorios no compartibles
3.- Directorios variables
4.- Directorios estáticos
1.- Directorios compartibles
Los directorios compartidos son aquellos
directorios que se pueden acceder desde distintos equipos. Por
lo tanto los directorios compartibles son aquellos que contienen
archivos que se pueden usar desde otros equipos.
Algunos ejemplos de directorios compartibles son:
/var/mail, /opt, /home, /var/www/html, /usr, etc.
2.- Directorios no compartibles
Al contrario que los directorios compartibles,
los directorios no compartibles son aquellos directorios que no
se pueden compartir y su acceso y modificación están limitados
al administrador del sistema. Por lo tanto los los directorios
no compartibles contienen archivos que solo puedes ser
accesibles y modificados por el administrador del sistemas.
Algunos ejemplos de directorios no compartibles son:
/etc, /boot, /var/run, etc.
3.- Directorios variables
Son aquellos directorios que contienen
archivos que pueden ser modificados y pueden variar su contenido
sin la intervención del administrador del sistema.
Algunos ejemplos de directorios variables son:
/var/log/messages, /var/mail, /var/spool/news, /home, /var/run,
etc.
4.- Directorios estáticos
Son aquellos directorios que contienen archivos que solo pueden
ser modificados con la intervención del administrador del
sistema.
Algunos ejemplos de directorios estáticos son:
/etc/password, /etc/shadow, /usr, /opt, /etc,
/boot, /bin, /sbin, etc.
ESTRUCTURA DE DIRECTORIOS EN GNU-LINUX
Directorio Raíz (/)
El directorio raíz, simbolizado por el símbolo (/), es el
directorio principal a partir del cual se ramifican todo el
resto de directorios.
Por lo tanto podemos decir que el directorio raíz es el
contenedor de nuestro sistema operativo ya que de él nacen el
resto de directorios que tendrá nuestro sistema operativo. Lo
que acabamos de comentar se puede ver representado en el
siguiente dibujo en que el directorio raíz es la rama principal
del árbol.
Árbol de directorios en LinuxÁrbol de directorios en Linux
Directorio /bin
El directorio /bin es un directorio estático y compartible en el
que se almacenan archivos binarios/ejecutables necesarios para
el funcionamiento del sistema. Estos archivos binarios los
pueden usar la totalidad de usuarios del sistema operativo.
Algunos de los archivos ejecutables almacenados en el directorio
/bin son cp, echo, tar, cat, mv, rm, ping, cp, gzip, kill, ls,
ping, su etc. Estos archivos son los que nos permiten realizar
la gran mayoría de utilidades básicas a través de la terminal
Linux.
El directorio /bin en ningún caso podrá contener subdirectorios.
Directorio /boot
Es un directorio estático no compartible que contiene la
totalidad de archivos necesarios para el arranque del ordenador
excepto los archivos de configuración. Algunos de los archivos
indispensables para el arranque del sistema que acostumbra a
almacenar el directorio /boot son el kernel y el gestor de
arranque Grub.
La totalidad de contenido almacenado en el directorio /boot es
el que se utiliza antes de que el Kernel de comience a ejecutar
programas en modo usuario.
El directorio /boot puede estar ubicado en su propia partición
(partición /boot).
Directorio /dev
El sistema operativo Gnu-Linux trata los dispositivos de
hardware como si fueran un archivo. Estos archivos que
representan nuestros dispositivos de hardware se hallan
almacenados en el directorio /dev.
Cada vez que nosotros accedemos o usamos un dispositivo de
hardware, como puede ser una memoria USB, una impresora, un
disco duro externo, un ratón, etc, accedemos al hardware del
dispositivo leyendo y escribiendo en el fichero correspondiente
ubicado en el directorio /dev.
Algunos de los archivos básicos que podemos encontrar en este
directorio son:
cdrom que representa nuestro dispositivo de
CDROM.
sda que representa nuestro
disco duro sata.
audio que representa
nuestra tarjeta de sonido.
psaux que representa el
puerto PS/2.
lpx que representa nuestra
impresora.
fd0 que representa nuestra
disquetera.
etc.
Directorio /etc
El directorio /etc es un directorio estático que contiene los
archivos de configuración del sistema operativo. Este directorio
también contiene archivos de configuración para controlar el
funcionamiento de diversos programas.
Algunos de los archivos de configuración de la carpeta /etc
pueden ser sustituidos o complementados por archivos de
configuración ubicados en nuestra carpeta personal /home.
Este directorio solamente contiene archivos de texto y
subdirectorios. Estos subdirectorios también contendrán archivos
de configuración para configurar partes de nuestro sistema como
por ejemplo:
/etc/apt: Carpeta que contiene ficheros de
configuración del gestor de paquetes apt.
/etc/opt: Carpeta que
contiene los ficheros de configuración para los programas
alojados en la carpeta /opt. Algunos programas alojados en esta
carpeta pueden ser Spotify, Google-earth, Google Chrome,
Teamviewer, etc.
/etc/profile: Carpeta que
contiene parámetros de configuración de los usuarios para
inicializar la shell o interprete de comandos “terminal”
/etc/sgml: Carpeta que
contiene los ficheros de configuración para SGML. SGML es un
lenguaje que se utiliza para la organización y marcado de
documentos.
/etc/X11: Ficheros para la
configuración del sistema X Window
etc.
Directorio /home
El directorio /home se trata de un directorio variable y
compartible. Este directorio está destinado a alojar la
totalidad de archivos personales de los distintos usuarios del
sistema operativo a excepción del usuario root. Algunos de los
archivos personales almacenados en la carpeta /home son
fotografías, documentos de ofimática, vídeos, etc.
Esta carpeta también contiene los ficheros de configuración de
los programas que utilizan cada uno de los usuarios del sistema
operativo a excepción del usuario root.
Todos los archivos personales y archivos de configuración que
acabamos de mencionar se almacenan en subdirectorios dentro de
la carpeta /home. Así por ejemplo si en nuestro ordenador
tenemos 2 usuarios (usuario1 y usuario2) los archivos personales
y de configuración del usuario 1 se almacenarán en la ubicación:
/home/usuario1
Por otro lado los archivos personales y de configuración del
usuario 2 se almacenarán en la carpeta:
/home/usuario2
De esta forma los archivos personales y de configuración quedan
perfectamente clasificados por usuario.
Normalmente el directorio /home reside un una partición propia.
El hecho que el directorio /home resida en una partición propia
es importante ya que de este modo podremos reinstalar nuestro
sistema operativo sin perder nuestros datos personales y
manteniendo la configuración antigua.
Nota: Haciendo un símil forzado con Windows,
la partición /home sería similar a la carpeta Mis documentos de
Windows.
Directorio /lib
El directorio /lib es un directorio estático y que puede ser
compartible. Este directorio contiene bibliotecas compartidas
que son necesarias para arrancar los ejecutables que se
almacenan en los directorios /bin y /sbin.
Este directorio también contiene módulos del kernel y
controladores de drivers que son necesarios durante el inicio
del sistema y durante el funcionamiento del sistema operativo.
Directorio /mnt
El directorio /mnt tiene la finalidad de albergar los puntos de
montaje de los distintos dispositivos de almacenamiento como por
ejemplo discos duros externos, particiones de unidades externas,
etc.
Los medios montados en esta carpeta pueden ser tanto estáticos
como variables y por norma general son compartibles.
Directorio /media
La función del directorio /media es similar a la del directorio
/mnt. Este directorio contiene los puntos de montaje de los
medios extraíbles de almacenamiento como por ejemplo memorias
USB, lectores de CD-ROM, unidades de disquete, etc.
En el directorio /media también podemos montar sin ningun tipo
de problema medios que montaríamos en el directorio /mnt.
Directorio /opt
El contenido almacenado en el directorio /opt es estático y
compartible. La función de este directorio es almacenar
programas que no vienen con nuestro sistema operativo como por
ejemplo Spotify, Google-earth, Google Chrome, Teamviewer, etc.
Como es un directorio compartible los programas presentes en
esta carpeta pueden ser usados por todos los usuarios del
sistema operativo.
La función de este directorio es muy similar a la del directorio
/usr/local, pero a diferencia de la carpeta /usr/local en /opt
se instalan programas que no siguen los estándares para
almacenar su contenido en la carpeta /usr.
Directorio /proc
El directorio /proc se trata de un sistema de archivos virtual.
Este sistema de archivos virtual nos proporciona información
acerca de los distintos procesos y aplicaciones que se están
ejecutando en nuestro sistema operativo.
Para cada uno de los procesos en marcha existe un subdirectorio
dentro de la carpeta /proc. Dentro del subdirectorio es donde se
almacena esta información.
Como curiosidad decir que la totalidad del contenido almacenado
en la carpeta /proc no está almacenado en nuestro disco duro. El
contenido de este directorio está almacenado en la memoria RAM y
el mismo sistema operativo es quien crea y borra el contenido de
la carpeta /proc.
Quien quiera más información acerca del directorio /proc puede
consultar el siguiente enlace.
Directorio /root
El directorio /root se trata de un directorio variable no
compartible. El directorio /root es el directorio /home del
administrador del sistema (usuario root).
Directorio /sbin
El directorio /sbin se trata de un directorio estático y
compartible. Su función es similar al directorio /bin, pero a
diferencia del directorio /bin, el directorio /sbin almacena
archivos binarios/ejecutables que solo puede ejecutar el usuario
root o administrador del sistema.
Los archivos incluidos en el directorio /sbin son aquellos que
son primordiales para el arranque, restauración y reparación del
sistema operativo. Algunos de los archivos ejecutables
almacenados en este directorio son fsck, init, reboot, shutdown,
fastboot, etc.
Otros directorios que contienen programas y binarios para la
administración del sistema son el /usr/bin y el /usr/local/sbin.
Directorio /srv
El directorio /srv se usa para almacenar directorios y datos que
usan ciertos servidores que podamos tener instalados en nuestro
ordenador.
Algunos de los servidores que almacenan datos en el directorio
/srv son:
Servidor web apache en el directorio /srv/www
Cualquier servidor ftp en
la ubicación /srv/ftp
Un servidor CVS.
Etc.
Directorio /tmp
El directorio /tmp es es donde se crean y se almacenan los
archivos temporales y las variables que los programas puedan
funcionar de forma adecuada.
Generalmente los sistemas operativos vacían el directorio /tmp
cada vez que reiniciamos el ordenador. En el caso que no sea así
es recomendable vaciar cada cierto el contenido de esta carpeta.
Directorio /usr
El directorio /usr es un directorio compartido y estático. Este
directorio es el que contiene la gran mayoría de programas
instalados en nuestro sistema operativo.
Todo el contenido almacenado en la carpeta /usr es accesible
para todos los usuarios y su contenido es solo de lectura.
El directorio /usr contiene una serie de subdirectorios que
acostumbran a almacenar la siguiente información:
/usr/bin: Subdirectorio que almacena los archivos ejecutables
del software que tenemos almacenado en nuestro ordenador.
/usr/include: Subdirectorio que incluye la totalidad de archivos
de cabecera que necesita el software instalado en nuestro
sistema operativo para que funcione de forma adecuada.
/usr/lib: Subdirectorio que incluye bibliotecas compartidas y
ficheros binarios que únicamente pueden ser ejecutados por el
administrador del sistema.
/usr/local: GNU-Linux es un sistema operativo diseñado para ser
usado en entornos de red. Por lo tanto es posible que el
directorio /usr no esté instalado localmente en nuestro y esté
en un servidor. En estos casos existe el directorio /usr/local
que está destinado a alojar los programas que instala localmente
el administrador del sistema. Este directorio está protegido de
las actualizaciones automáticas de todo el sistema operativo y
tiene una estructura de directorios muy similar a la del
directorio /usr.
/usr/sbin: Directorio que contiene archivos binarios para la
administración del nuestro equipo no esenciales para el proceso
de arranque ni para reparar el ordenador. Estos archivos
binarios almacenados en la carpeta /usr/sbin solamente pueden
ser usados por el administrador del sistema. Algunos de estos
archivos binarios no críticos para administrar el sistema
operativo pueden ser por ejemplo varios demonios para diversos
servicios de red, xcalib para calibrar el color de nuestro
monitores, etc.
/usr/share: En el directorio /usr/share encontramos archivos de
texto compartibles que son independientes de la arquitectura del
sistema operativo. En este directorio podemos encontrar por
ejemplo los archivos de ayuda como por ejemplo los documentos
info y las páginas de man, ficheros de configuración, imágenes,
iconos, themes, etc.
/usr/src: En el directorio /usr/src normalmente encontramos el
código fuente de algunas aplicaciones y del kernel que tenemos
instalado en nuestro sistema operativo.
Directorio /var
El directorio /var contiene archivos de datos variables y
temporales como por ejemplo los registros del sistema (logs),
los registros de programas que tenemos instalados en el sistema
operativo, archivos spool, etc.
La principal función del directorio /var es la detectar
problemas y solucionarlos. Se recomienda ubicar el directorio
/var en una partición propia, y en caso de no ser posible es
recomendable ubicarlo fuera de la partición raíz.
Algunos de los subdirectorios importantes que están dentro de la
carpeta /var son los siguientes:
/var/cache: Subdirectorio pensado para almacenar datos de
aplicaciones en modo cache. Un ejemplo de lo que acabo de citar
es apt-get. En el momento de instalar una aplicación con apt-get
se almacena una copia del paquete binario instalado en la
ubicación /var/cache/apt/archives/. Así en el caso que
desinstalaramos el programa y quisiéramos volver instalarlo no
seria necesario descargar el fichero binario de nuevo y la
instalación seria inmediata.
/var/lib: En este subdirectorio encontramos información sobre el
estado de las aplicaciones. Este directorio también contiene
bases de datos del sistema.
/var/lock: Directorio en el que se hallan los archivos de
bloqueo que crean ciertos programas. La función de los archivos
de bloqueo creados por algunos programas, como por ejemplo un
servidor web, es evitar que ciertos recursos sean usados por
otros programas que no sean el propio servidor web. En el
momento de cerrar la aplicación que ha generado el archivo de
bloqueo, el archivo de bloqueo desaparece.
/var/log: En el directorio /var/log se encuentran de forma
clasificada gran parte de los registros de nuestros programas y
del sistema operativo. Este directorio es muy importante ya que
en caso de problemas, el administrador del sistema lo puede
consultar para intentar averiguar la causa del problema. Los log
o registros se encuentran perfectamente clasificados, así por lo
tanto si queremos consultar los registros generados por el
kernel tendremos que consultar el archivo /var/log/messages, si
queremos consultar los accesos a nuestro sistema operativo
podemos consultar el archivo /var/log/wtmp, etc.
/var/mail: Directorio en el que se ubican los archivos de correo
electrónico de cada uno de los usuarios del servidor de mail.
También es posible ubicar nuestros archivos de correo
electrónico en la partición /home.
/var/opt: En el directorio /var/opt se almacenan datos variables
que utilizan los programas instalados en la ubicación /opt.
/var/run: El directorio /var/run contiene información de la
sesión que estamos ejecutando. Ejemplos de la información que
contienen los archivos de esta carpeta son los demonios que
están en ejecución, los usuarios que están logueados, los
procesos que están activos, etc.
/var/spool: Directorio que almacena archivos que controlan la
tareas pendientes de realizar. Así por ejemplo en el directorio
/var/spool/cups encontraremos los archivos que gestionan los
trabajos de impresión en espera, en el directorio
/var/spool/cron encontraremos los archivos que gestionan las
tareas planificadas pendientes de ejecutar, etc.
/var/tmp: Directorio que al igual que el directorio /tmp
contiene archivos temporales. La principal diferencia entre los
directorios /var/tmp y /tmp es que los archivos temporales
ubicados en la carpeta /tmp se acostumbran a borrar
automáticamente entre sesiones o reinicios del sistema, mientras
que los archivos temporales ubicados en el directorio /var/tmp
no lo hacen.
Directorio /sys
Directorio que contiene información similar a la del directorio
/proc. Dentro de esta carpeta podemos encontrar información
estructurada y jerárquica acerca del kernel de nuestro equipo,
de nuestras particiones y sistemas de archivo, de nuestros
drivers, etc.
Directorio /lost+found
Directorio que se crea en las particiones de disco con un
sistema de archivos ext después ejecutar herramientas para
restaurar y recuperar el sistema operativo como por ejemplo
fsch.
Si nuestro sistema no ha presentado problemas este directorio
estará completamente vacío. En el caso que hayan habido
problemas este directorio contendrá ficheros y directorios que
han sido recuperados tras la caída del sistema operativo.
Para finalizar solo comentar que espero que esta pequeña
explicación les haya sido útil para tener una idea genérica del
contenido que se encuentra en cada una de las carpetas de
nuestro sistema operativo.
Shell
Comandos del sistema que son útiles (realicen
estos comandos en una terminal, repaso)
Comando pwd
El comando pwd significa “directorio de trabajo de impresión” y
es un comando de Linux simple pero útil. Este comando se usa
para mostrar el nombre de su directorio actual, lo que puede ser
útil al navegar por el sistema de archivos.pwd
pwd
Comando cd
El comando cd de Linux se usa para cambiar el directorio de
trabajo actual de un usuario. Se puede usar para subir un nivel
en el sistema de archivos, o se le puede dar un directorio como
argumento para cambiar el directorio de trabajo.
(para ir al home por defecto del usuario)
[msantos@alienware ~]$ cd
[msantos@alienware ~]$
(para devolverse o salir desde la carpeta en
la que estás posicionado)
cd ..
(para ingresar a una carpeta)
cd carpeta
(para saltar entre directorios)
cd /home/usuario/public_html
Comando ls
El comando ls es una utilidad de línea de
comandos que enumera el contenido de un directorio.
Se utiliza para enumerar archivos y directorios en sistemas
operativos Unix y similares a Unix, incluido Linux.
El comando ls se puede utilizar con los siguientes parámetros:
-l (lista en formato largo)
-a (enumera todos los archivos, incluidos los
ocultos)
-t (ordenar por hora de última modificación)
-S (ordenar por tamaño de archivo)
Ejemplos:
ls -l
ls -la (muy usado debido a que complementa dos
flags completos)
(realizaremos una explicacion de este comando
mas extensa)
(Ver la lista completa de archivos dentro de
carpetas se dice que es de forma recursiva, hay que
realizarlo en la terminal)
ls -lR
Es un gran listado para poder ver los
directorios de forma pausada, es usando el comando more (mas)
formando un entubamiento (|):
ls -lR | more
cuando llega al final, de la pagina se muestra
una palabra --Más-- realiza una pausa, para observar esto, con
la barra espaciadora avanza a otra pagina, y seguirá mostrando
--Más -- hasta que el total de directorios y archivos termina de
mostrarse todos los directorios, y usando la tecla de ENTER
avanza de renglon en renglon.
Realizaremos un comando que crea archivos
vacios (?), asi es, crea archivos vacios, estos tienen muchas
funciones en el sistema, por el momento lo haremas asi:
[msantos@alienware
~]$ touch recipientes
usando ls -l lo veremos asi:
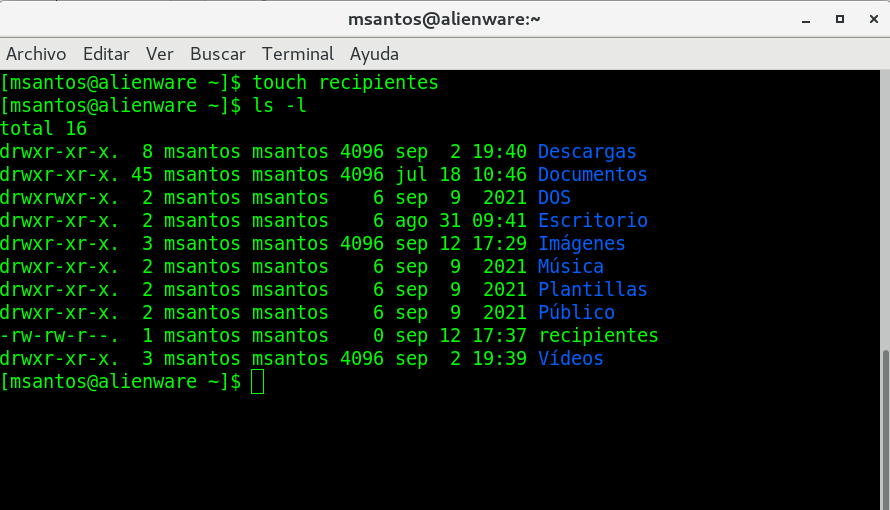
revisemos que esta sucediendo (veamos en las
notas anteriores sobre las caractristicas de los archivos
|
- - -
|
= 0
|
no se tiene ningún permiso
|
|
- - x
|
= 1
|
solo permiso de ejecución
|
|
- w -
|
= 2
|
solo permiso de escritura
|
|
- w x
|
= 3
|
permisos de escritura y ejecución
|
|
r - -
|
= 4
|
solo permiso de lectura
|
|
r - x
|
= 5
|
permisos de lectura y ejecución
|
|
r w -
|
= 6
|
permisos de lectura y escritura
|
|
r w x
|
= 7
|
todos los permisos establecidos, lectura,
escritura y ejecución
|
El primer carácter al extremo izquierdo,
representa el tipo de archivo, los posibles valores para esta
posición son los siguientes:
- un guión representa un archivo comun (de
texto, html, mp3, jpg, etc.)
d representa un directorio
l link, es decir un enlace o acceso directo
b binario, un archivo generalmente ejecutable
Los siguientes 9 restantes, representan los
permisos del archivo y deben verse en grupos de 3.
Los tres primeros representan los permisos
para el propietario del archivo. Los tres siguientes son los
permisos para el grupo del archivo y los tres últimos son los
permisos para el resto del mundo o otros.
rwx
rwx rwx
usuario grupo otros
entonces que podemos concluir ?
Ahora editaremos este archivo, y le
agregaremos algún texto:
con vi creamos un archivo de texto el primero con
el nombre de recipientes
[msantos@alienware ~]$ vi recipientes
y contendrá lo siguiente:
la gran mayoria de textos son para
procesamiento de datos,
como almacenamiento de información tal como si fueran tablas
de datos
por lo que los procesos se realizan muy rapido
ya que no tienen una estructura compeja
que sera usado en ejercicio mas adelante,
y para comenzar a escribir un texto, usamos la letra i
<insertar> y comenzamos a escribir nuestro texto (se
pueden utilizar las teclas del movimiento del cursor:
para terminar usamos la tecla Esc,y a
continuacion escribimos :wq que significa -> ejecuta(:)
escribe(w) salir(q)
al regresar al directorio podemos ver algo
asi:

ya no esta vacio, se edito y contine texto.
Comando cat
cat, aunque es un comando simple en su nivel más básico, es uno
de los comandos de Linux más utilizados en el sistema. Significa
“concatenar” y se usa para mostrar lo que hay dentro de un
archivo de texto. Solo puede usar cat si conoce el nombre y la
extensión del archivo que desea mostrar.
cp, este comando sirve para copiar archivos
[msantos@alienware
~]$ cp recipientes recipientes1
copia recipientes a otro archivo llamado recipientes1,
contienen lo mismo
[msantos@alienware
~]$ cat
recipientes recipientes1

cat recipientes recipientes1 (cat puede
mostrar varios archivos en la misma instruccion del comando)
touch no se queda atras puede crear varios
archivos vacios:
[msantos@alienware
~]$ touch arch1 arch2 arch3 arch4
arch5
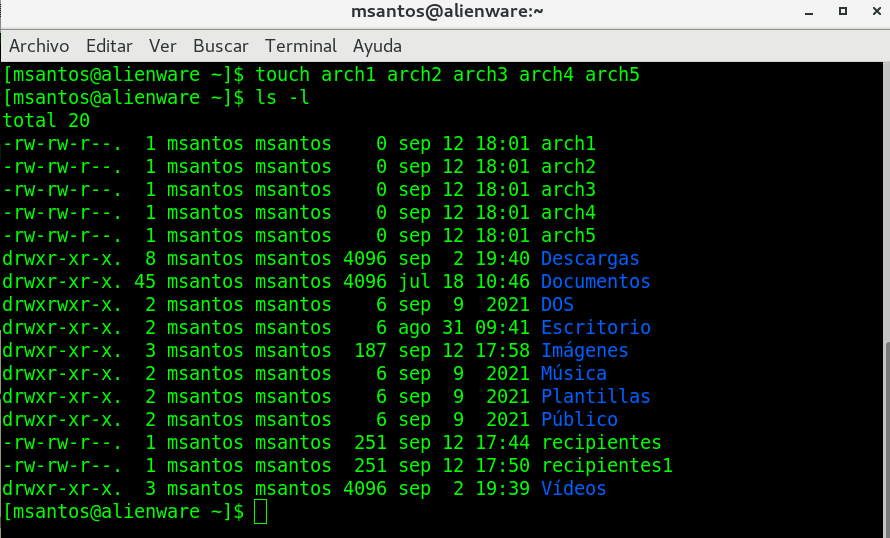
crearemos 3 directorios con los nombres de
recip1 recip2 recip3:
[msantos@alienware
~]$ mkdir recip1 recip2 recip3
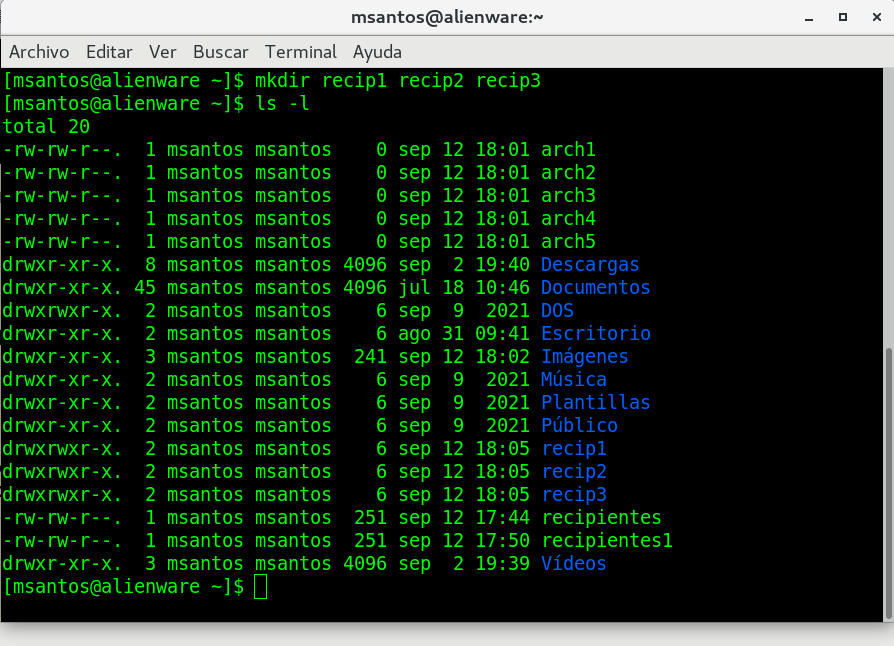
Actividad: se mostrara la forma de crear
directorios dentro de directorios, mostrando la forma y
estructura del sistema de archivos, entrar salir, la actividad
la realizara el instructor, con ejemplos y los alumnos
realizaran este ejercicio y sera a consideración del alumno.
Rutas absolutas y rutas relativas
La ruta es uno de los conceptos más esenciales
en Linux y esto es algo que todo usuario de Linux debe saber.
Una ruta es la forma de referirse a los archivos y directorios.
Nombres de archivos
Los nombres de archivos en GNU/Linux pueden
tener hasta 255 caracteres, pudiendo utilizar los espacios y
acentos. Hay una excepción solo en cuanto al uso de los
caracteres especiales / \ | » * ? < > ! `.
Da la ubicación de un archivo o directorio en
la estructura de directorios de Linux. Se compone de un nombre y
de la sintaxis de la barra diagonal.
Ruta absoluta y relativa en Linux
La ruta absoluta siempre comienza en el
directorio raíz (/). Por ejemplo, /home/itsfoss/scripts/mi_scripts.sh.
Una ruta relativa comienza desde el directorio actual. Por
ejemplo, si se encuentra en el directorio /home y desea acceder
al archivo mi_script.sh, puede utilizar
itsfoss/scripts/mi_script.sh.
Entender la diferencia entre rutas absolutas y relativas
Ya sabes que la estructura de directorios en
Linux se parece a la raíz de un árbol. Todo comienza en la raíz
y se ramifica desde allí.
Ahora imagina que estás en el directorio itsfoss y quieres
acceder al archivo mi_script.sh.
La ruta absoluta está representada en la línea punteada verde y
la ruta relativa está representada en las líneas punteadas
amarillas.
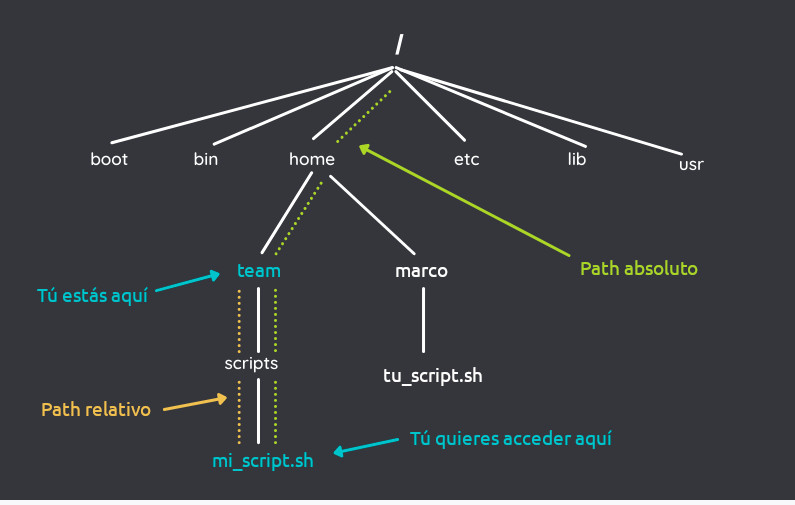
Supongamos que quieres ver las propiedades del
archivo mi_script.sh utilizando el comando ls.
Puedes utilizar la ruta absoluta que comienza con el directorio
raíz (/):
ls -l /home/itsfoss/scripts/mi_script.sh
O bien, puedes utilizar la ruta relativa (que
comienza en el directorio actual, no en /):
ls -l scripts/mi_script.sh
Ambos comandos darán el mismo resultado
(excepto la ruta del archivo).
team@itsfoss:~$ pwd
/home/team
team@itsfoss:~$ ls -l /home/team/scripts/mi_script.sh
-rwxrw-r-- 1 team itsfoss 33 Jan 30 15:00
/home/team/scripts/mi_script.sh
team@itsfoss:~$ ls -l scripts/mi_script.sh
-rwxrw-r-- 1 team itsfoss 33 Jan 30 15:00 scripts/mi_script.sh
usemos el comando touch para crear los
siguientes archivos en nuestro directorio casa (/home/usuario)
touch arch1 arch2 arch3 arch4
arch5
creamos los siguientes
directorios
mkdir recip1 recip2 recip3
Usando cp podemos copiar los archivos a
los directorios de recip1, recip2 y recip3:
[msantos@alienware ~]$ cp arch1
arch2 recip1/
[msantos@alienware ~]$ cp arch3 arch4 recip2/
[msantos@alienware ~]$ cp arch5 recip3/
Observe que se han agregado la diagonal al
final del nombre, esto significa que es un directorio, (los que
se crearon antes con mkdir) para verificar que se han copiado a
estos directorios los archivos realizamos esto:
[msantos@alienware ~]$ ls -l
recip1/
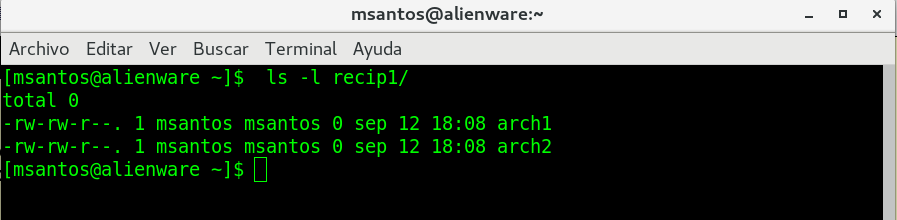
vea la sintaxis: ls -l recip1/ (obseva algo
interesante ?) ahora estos:
[msantos@alienware ~]$ ls -l recip2/ recip3/
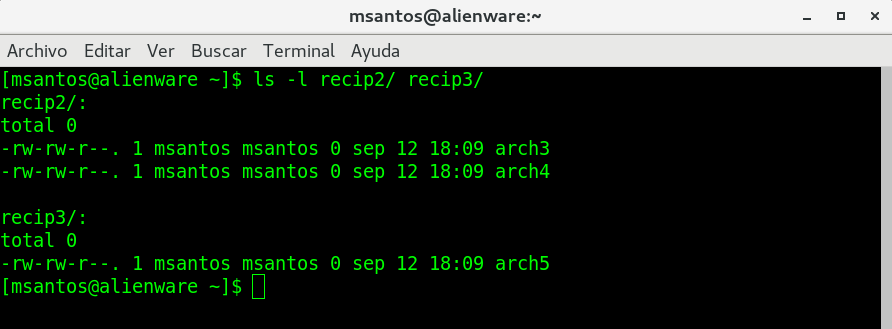
espero tus comentarios
Ahora borrar estos archivos:
rm -> remove es decir todo lo que esta en
el interior de cada directorio, para que actue se requiere que
este dentro del directorio:
[msantos@alienware
recip1]$ ls -l
[msantos@alienware recip1]$ rm *
[msantos@alienware recip1]$ ls -l
rm * remueve todos los archivos (*
caracter comodin que toma todo lo que se encuenra en los
archivos)
[msantos@alienware recip1]$ cd ..
[msantos@alienware ~]$ pwd
[msantos@alienware ~]$ cd recip2/
[msantos@alienware ~]$
pwd
/home/msantos/recip2
[msantos@alienware
recip2]$ ls -l
[msantos@alienware
recip2]$ rm *
[msantos@alienware recip2]$ ls -l
total 0
cd .. esto significa que retrocedemos al nivel
superior del directorio
[msantos@alienware
recip2]$ cd ..
en este caso el comando rm
remueve los archivos, usese con cuidado, si se aplica de forma
incorrecta puede dañar el contenido del directorio y perdera
de forma definitiva los archivos.
regresamos al directorio home del usuario : cd
usted borre el archivo recipientes1, y realice de nuevo
el archivo de nombre recipientes1, que escribira un texto de 4
lineas, deberá ser corto, por el momento realice esto:
mover los arcivos llamados arch1 arch2 a
recip1/
mv arch1 arch2
recip1/
[msantos@alienware ~]$ mv arch3
arch4 recip2/
[msantos@alienware ~]$ ls -l
[msantos@alienware
~]$ mv arch5 recip3/
[msantos@alienware ~]$ ls -l
[msantos@alienware
~]$ ls -l recip1/ recip2/ recip3/
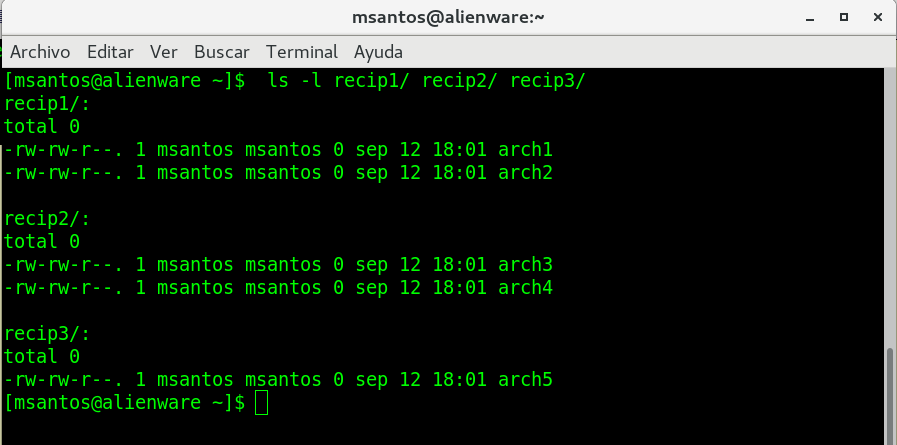
ahora la segunda forma de mv, cambiar de
nombre:
[msantos@alienware ~]$ cd
recip3/
[msantos@alienware recip3]$ ls -l
[msantos@alienware recip3]$
mv arch5 archivo_con_nombre
[msantos@alienware recip3]$ ls -l
puedes ver la diferencia ?
ahora debemos de conocer esto:
El shell proporciona varias
opciones a la hora de digitar los comandos, tales como: (4)
|
SIMBOLO
|
SIGNIFICADO
|
|
*
|
Metacaracteres para usar varios
archivos o directorios. |
|
?
|
Reemplaza
un solo caracter |
|
&
|
Comandos
en background, ej: find > archivo & |
|
;
|
Ejecutar
varios comandos, ej: $ ls ; pine |
|
|
|
Para
dirigir salidas standard. |
|
>
|
Redireccionar
la salida estandar a un archivo. |
|
>>
|
Lo mismo
que el anterior pero no sobreescribe. |
|
<
|
Para tomar los datos de un archivo. |
usemos estas opciones
para mostrar el directorio usamos ls -l, y
este listado del directorio lo enviamos a un archivo:
cd
ls -l >
directorio
y al revisar en el directorio
:
[msantos@alienware ~]$ ls -l
> directorio
[msantos@alienware ~]$ ls -l
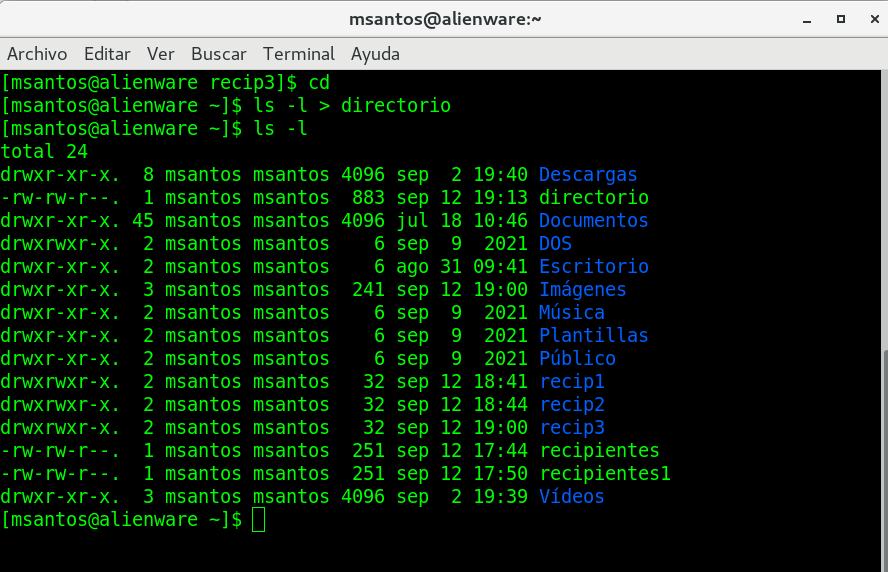
[msantos@alienware ~]$ cat directorio
Ahora:
[msantos@alienware ~]$ cat
recipientes >> directorio
[msantos@alienware ~]$ cat directorio
Une el archivo recipientes al archivo directorio, si
usáramos > en lugar de >> el archivo recipientes
sobrescribe a directorio
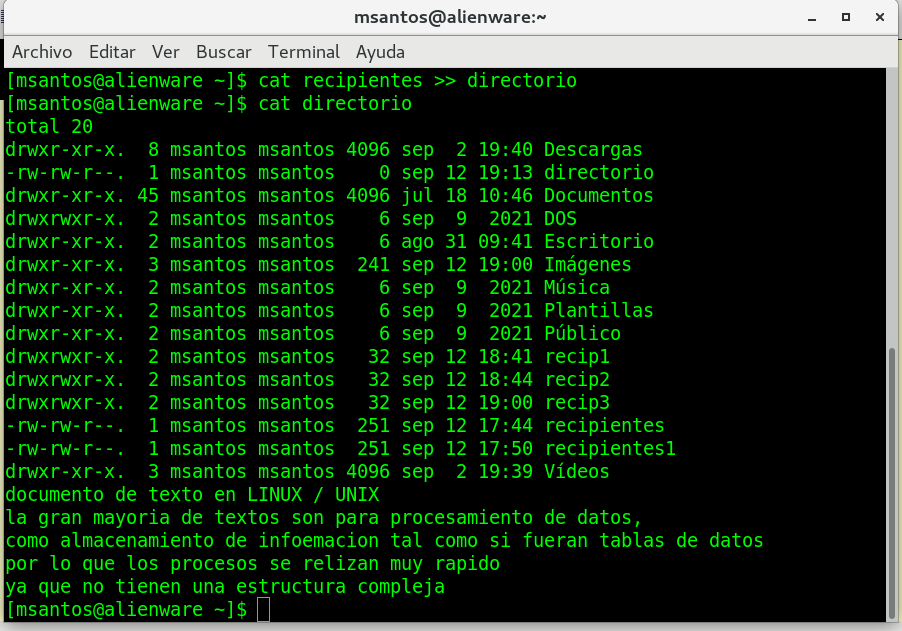
repita lo anterior con el archivo que creo con el nombre
recipientes1, y vea el resultado.
Usemos el comando sort, formemos un
archivo y escriba nombres de personas, solo sus
nombres :
[msantos@alienware ~]$ touch
nombres
[msantos@alienware ~]$ vi nombres
Guardamos el contenido del archivo Esc :wq,
aplicamos el comando sort
[msantos@alienware
~]$ sort nombres

hasta aqui solo los ordena en
linea, para guardarlos en otro archivo y consevar el original
sin cambios:
[msantos@alienware ~]$ sort
nombres > nombres_ordenados
[msantos@alienware ~]$ cat nombres_ordenados
[msantos@alienware ~]$
cat nombres

grep (Globally
Search For Regular Expression and Print out "Búsqueda global
de expresiones regulares")
es un comando para "buscar"
una cadena dentro un archivo, en un contenido de listado, o en
linea de comando.
[msantos@alienware ~]$ cat
nombres_ordenados | grep miguel

esta opción de | (se
le conoce como pipe) es para "entubar" de comando hacia
otro.
[msantos@alienware ~]$ grep
'ruben' nombres

hay muchos mas comandos en shell bash
(Bourne-again shell) (5)
uptime
uptime es el comando más utilizado para
determinar rápidamente el tiempo que lleva en ejecución el
sistema:
En este caso, nos informa que son 57 minutos. Como se podrá
observar también nos da la hora actual, usuarios conectados y
la carga promedio de uso de los CPU(s). Informativo, pero si
queremos determinar a que hora exacta inicio el sistema,
tendríamos que hacer una resta de la hora actual con el tiempo
"up", no muy intuitivo, asi que para eso tenemos la opción -s:
uptime también tiene otra opción (no tiene
muchas), la opción -p (pretty) que da la información de "up" un
poco más entendible:
Nota: las opciones -s y -l están disponibles
en la versión 3.3 y superior del comando uptime. La versión se
determina con la opción -V.
Con el comando who y la opción -b es posible
obtener también la fecha y la hora de inicio del sistema:
Tambien se puede usar con la opción -r es útil
para determinar el último cambio de runlevel o nivel de
ejecucción del sistema:
(O las dos opciones a la vez:)

El comando last despliega una lista de los últimos usuarios
que se han logueado al servidor. Pero también muestra cuando
fue reiniciado el sistema:

O utiliza 'reboot' después de last para ver
una lista mas compacta:)
El comando w muestra los usuarios conectados y
lo que están haciendo, y también muestra, al igual que uptime,
de hecho, exactamente igual que uptime muestra la hora actual,
el tiempo up, usuarios conectados y carga del CPU(s)
Si no deseas que w muestre la primera línea de
su salida, utiliza entonces la opción -h
echo
Mostrar el shell en uso:
Entorno del usuario
Nombre del usuario actual:
Nombre del equipo:
Directorio base del usuario actual:
Directorio de trabajo actual:

Comando
tree
En ocasiones la navegación por los directorios de Linux
desde la consola se hace un poco complicada, además, en
algunos casos necesitamos conocer la estructura de algunos
directorios, la manera natural de mejorar esto, es mostrando
los directorios en forma de árbol.
Mostrar los directorios en forma de árbol en Linux es bastante
sencillo, gracias a la utilidad tree, la cuál, no viene
instalada por defecto en la mayoría de las distribucciones
Linux pero que si se encuentran en los repositorios oficiales.
Como superusuario:
yum install tree -y

tree
# Muestra directorios y ficheros
$ tree -d # Muestra
sólo directorios
$ tree -L X # Muestra hasta X
directorios de profundidad
$ tree -f # Muestra
los archivos con su respectiva ruta
$ tree -a # Muestra todos
los archivos, incluidos los ocultos.
$ tree / #
Muestra un árbol de todo nuestro sistema
$ tree -ugh # Muestra los ficheros con su
respectivo propietario (-u),
el grupo (-g) y el tamaño de cada archivo (-h)
$ tree -H . -o tudirectorio.html # Exporta tu árbol de
directorio a un archivo HTML
Comando whoami
El comando whoami es un comando
sumamente sencillo el cual muestra el identificador del
usuario actual.
EJERCICIOS A REALIZAR
<alumno> sera el usuario creado en la instalación
inicial.
Crear directorios Practicas y Trabajos
en Practicas crear directorios Sistemas y Prog
en Prog crear fuentes y enunciados
revisar del lado dl directorio trabajos los directorios
correspondientes.
Crear ficheros de texto en los directorios: "pdf", "word",
"fuentes", "enunciados", "si", etc
Copiar ficheros y directorios (recursivo), utilizando rutas
absolutas y rutas relativas para identificar directorios de
origen y destino
Realizar ejercicio análogo al anterior utilizando pero
moviendo
Eliminar ficheros y directorios (recursivo) de los árboles
resultantes de los ejercicios anteriores, utilizando rutas
absolutas y relativas
Sea el fichero "trabajo.txt" situado en el directorio home.
¿Qué permisos se le deben habilitar para que cualquier
otro usuario pueda leerlo?
Siendo el mismo fichero, ¿qué permisos se
deben habilitar para que lo puedan leer sólo los usuarios del
mismo grupo al que está asignado el fichero?
Comando file es un comando de la familia de
los sistemas operativos Unix, que permite detectar el tipo y
formato de un archivo. Para lograrlo, analiza el encabezado, el
número mágico o bien el contenido que el archivo posea.
Preguntas teóricas generales (FAQ)
¿Por qué decimos que "Linux"
es solamente el kernel del sistema operativo que utilizamos?
Respuesta: Linux es el
nombre del kernel del sistema operativo GNU/Linux. El resto
del sistema fue desarrollado por el proyecto GNU y por eso se
llama GNU/Linux.
¿Qué representa cada una de las columnas que
vemos por pantalla al ejecutar un ls -l?
-rw-r--r-- 1 marga
marga
0 2003-02-08 00:42 test
Respuesta: La primera columna indica
si se trata de un directorio (d), un archivo (-), un symlink
(l), etc. A continuación se indican los permisos del
archivo, para el dueño, el grupo y el resto de los usuarios.
La segunda columna indica la cantidad de links al inodo, la
tercera y la cuarta son el dueño y el grupo del archivo. La
sexta columna inidica el tamaño del archivo, seguida por la
fecha y la hora de modificación, y finalmente el nombre del
archivo.
¿Que son los meta-caracteres de shell? ¿Para
qué se utilizan? Cite algunos ejemplos.
Respuesta: Los
meta-caracteres de shell son caracteres especiales que son
interpretados por el shell antes de que la información sea
enviada a los comandos.
De esta manera, ejecutar echo * no el envía al comando echo un
*, sino que le envía el listado de todos los archivos y
directorios que se encuentran en el directorio actual.
Ejecutar ps ax > procesos, por otro lado, hace que la
salida del comando ps no se vea en la pantalla del usuario,
sino que se guarde en el archivo procesos.
Si se ejecuta ls -l ?????, se obtendrá un listado con toda la
información de los archivos que tengan cinco letras en su
nombre.
Y si se ejecuta (sleep 300; echo "Ya está el agua para el té")
&, el shell devuelve la línea de comandos inmediatamente,
pero a la vez se genera un proceso que espera 5 minutos y
luego muestra un mensaje por pantalla avisando que ya está
hirviendo el agua.
¿Cómo se determina en los sistemas UNIX el
tipo de un archivo?
Respuesta: En los sistemas
UNIX el tipo de un archivo no se determina por su extensión,
sino por su contenido. El comando file analiza el contenido de
un archivo y determina el tipo del mismo, según una serie de
reglas.
¿En qué consiste el dispositivo /dev/tty
Respuesta: El dispositivo
/dev/tty es la consola actual que está utilizando el usuario.
De modo que ejecutar el comando echo Hola > /dev/tty,
mostrará "Hola" en la pantalla del usuario.
¿Qué es una variable de entorno? ¿Qué
variables de entorno son heredadas por las aplicaciones que se
ejecutan?
Respuesta: Una variable de
entorno es una de las variables que pertenecen al sesión de un
determinado usuario. Muchas de estas variables adquieren un
valor en el momento que el usuario ingresa al sistema,
mientras que algunas otras pueden adquirir un valor
posteriormente, si el usuario ejecuta variable=valor. Las
únicas variables de entorno que son heredadas por las
aplicaciones son aquellas que fueron exportadas usando el
comando export.
¿Cuál es la función principal de un "filtro"?
Cite algunos filtros y su funcionalidad básica.
Respuesta: Los filtros son
programas que procesan una determinada entrada y muestran una
salida relacionada con la entrada recibida. cat, uno de los
filtros más sencillos, simplemente muestra una salida idéntica
a la entrada. head y tail, otros filtros bastante sencillos,
muestran el principio y el final de la entrada
respectivamente. grep, un filtro bastante más avanzado,
muestra únicamente ciertas líneas de la entrada, según el
patrón y las opciones que se le indiquen.
¿En que consiste una "Expresion Regular". De
algunos ejemplos.?
Respuesta: Una
expresión regular es una cadena de caracteres que se utiliza
para concordar con palabras o líneas de texto de una forma más
o menos compleja. Una palabra sencilla, como "Nicolás" por
ejemplo, puede ser una expresión regular, ya que coincidiría
con todas las apariciones de la palabra Nicolás. Pero las
expresiones regulares son mucho más poderosas, permiten
especificar que una palabra esté al comienzo o al final de la
línea, que tenga un rango de caracteres en medio, etc, etc.
Por ejemplo, la expresión ^A.*o$, coincidirá con las líneas
que comiencen con A y terminen con o, esto podría coincidir
tanto con "Alejandro" como con "Antes de ayer vi un mono". La
expresión ^P[^ ]*o$, por otro lado coincidirá con las palabras
que comiencen con P, terminen con o y no tengan ningún espacio
en medio, es decir, podrá coincidir con "Pedro" o "Pablo",
pero no con "Paso a paso".
Ejercicios Prácticos -
Archivos, permisos y propiedad
¿De qué manera podemos evitar que los otros
usuarios puedan ver el contenido de un directorio?
Si el directorio en cuestión se llama, por
ejemplo, "secretos", podríamos ejecutar chmod 711 secretos, con
lo que quitaríamos el permiso de lectura, necesario para ver el
contenido del directorio. También podríamos ejecutar chmod
go-rwx secretos para quitarle todos los permisos tanto al grupo
como a los otros usuarios.
¿Cómo podemos hacer para que el archivo
"ulises" tenga los siguientes permisos?
De lectura y
escritura, solo para el dueño del archivo.
chmod ??? ulises
De lectura y
ejecución para todos los usuarios.
chmod ??? ulises
De lectura para todos
los usuarios, y escritura solo para el dueño del archivo.
chmod ??? ulises
¿Qué permisos asigna el comando "chmod 755
/bin" ? ¿Por qué, cuando ejecutamos este comando, nos dice que
no poseemos los permisos necesarios?
Ese comando le dá todos los permisos al dueño
del directorio (root), y permisos de lectura y ejecución a los
miembros del grupo y al resto de los usuarios.
Cuando lo tratamos de ejecutar nos dice que
no tenemos los permisos necesarios para ejecutarlo, porque
solamente el dueño del archivo (o el administrador del sistema
puede cambiar los permisos a un archivo o directorio, y en este
caso el dueño es root, y no un usuario común.
Explique qué permisos asignan o desasignan
los siguientes comandos:
Le dá a los usuarios que no son el dueño del
archivo, ni pertenecen al grupo del archivo el permiso de ver el
contenido del archivo.
chmod ??? carta
Le dá todos los permisos al dueño y permisos
de lectura y ejecución al
resto
chmod ???
/bin
Le dá todos los permisos al dueño y permisos
de lectura y ejecución al resto
Sobre el directorio /usr/bin
¿Qué tipo de archivos hay en ese directorio?
¿Cuáles son los permisos del directorio?
Para ver los permisos del directorio
utilizamos el comando ls, con la opción -d, para que no muestre
el contenido, sino el directorio en si: ls -ld /usr/bin.
drwxr-xr-x 4
root
root 45056 2003-05-31
20:35 /usr/bin
El directorio tiene todos los permisos para
el dueño y permisos de lectura y ejecución para el resto de los
usuarios.
¿Cómo se expresan esos permisos en forma
octal con chmod?
¿Por qué el directorio debe tener esos
permisos, y no otros?
Para que todos los usuarios puedan ver y
acceder a los archivos ejecutables que se encuentran allí, pero
solamente el dueño del directorio (root) pueda agregar o quitar
archivos del directorio.
Explicar qué sucede cuando queremos cambiar
los permisos del directorio
Si queremos ejecutar chmod 000 /usr/bin nos
indica que no tenemos permiso para realizar esa operación, ya
que solamente el dueño de un archivo o directorio, y el
administrador del sistema pueden cambiar sus permisos.
Sobre el directorio /etc
¿Qué tipo de archivos hay en ese directorio?
Son archivos de configuración
del sistema
Compare y explique los permisos de los
archivos /etc/passwd y /etc/shadow
-rw-r--r--
1 root
root 1399
2003-03-30 23:39 /etc/passwd
-rw-r----- 1
root
shadow 936
2003-03-23 07:30 /etc/shadow
El archivo /etc/passwd
tiene permisos de lectura y escritura para el dueño (root) y
sólo de lectura para el resto de los usuarios, mientras que el
archivo /etc/shadow tiene los mismos permisos para el dueño,
pero solamente tiene permisos de lectura para los que
pertenezcan al grupo del archivo (shadow). Esto se debe a que en
el archivo /etc/shadow se almacenan las contraseñas de los
usuarios (encriptadas), y no es deseable que este archivo pueda
ser leído por cualquier usuario.
(1)
http://docencia.udea.edu.co/cci/linux/dia8/shell.html
(2)
https://es.linux-console.net/?p=1931&PageSpeed=noscript
(3)
https://blog.desdelinux.net/comandos-para-conocer-el-sistema-identificar-hardware-y-algunas-configuraciones-de-software/
(4) http://docencia.udea.edu.co/cci/linux/dia8/shell.html
(5) https://es.wikipedia.org/wiki/Bash
https://www.cesareox.com/docencia/apuntes/linux/#7
http://vis.usal.es/~visusal/insa/ejercicios.pdf
https://bioinf.comav.upv.es/courses/unix/scripts_bash.html#ejercicios
http://www.gnuservers.com.ar/cursos/inicial/ejercicios.html
http://www.gnuservers.com.ar/cursos/inicial/respuestas.html







































 Conector M.2
Conector M.2



















 Permite introducir el tercer carácter
de una tecla, por ejemplo, @, #, etc. ,es utilizada en los
teclados Latinoamericanos y/o Español para poder agregar símbolos
especiales que están al lado derecho de las teclas, también
llamados caracteres mudos, porque al realizar la operación de
selección es la tecla Alt Gr + Tecla con el carácter mudo, solo se
podrá observar si después de esta acción se presiona la barra
espaciadora.
Permite introducir el tercer carácter
de una tecla, por ejemplo, @, #, etc. ,es utilizada en los
teclados Latinoamericanos y/o Español para poder agregar símbolos
especiales que están al lado derecho de las teclas, también
llamados caracteres mudos, porque al realizar la operación de
selección es la tecla Alt Gr + Tecla con el carácter mudo, solo se
podrá observar si después de esta acción se presiona la barra
espaciadora.
 Permite introducir el segundo
carácter de una tecla, por ejemplo ( ! " # $ % & / ( ) = ?
� ] > * : ; ).
Permite introducir el segundo
carácter de una tecla, por ejemplo ( ! " # $ % & / ( ) = ?
� ] > * : ; ).
 La tecla Tabulador sirve para
desplazarse entre los elementos (opciones, cuadros de texto,
pestañas, botones) de una ventana.
La tecla Tabulador sirve para
desplazarse entre los elementos (opciones, cuadros de texto,
pestañas, botones) de una ventana.
 Tecla usada para aceptar la selección
de alguna opción o la ejecución de una operación. Funciona algunas
veces como un clic y otras como un doble clic, dependiendo de la
acción que se esté ejecutando, También se le conoce como Intro.
Tecla usada para aceptar la selección
de alguna opción o la ejecución de una operación. Funciona algunas
veces como un clic y otras como un doble clic, dependiendo de la
acción que se esté ejecutando, También se le conoce como Intro.
 Tecla usada para cancelar una
operación o salir de una pantalla
Tecla usada para cancelar una
operación o salir de una pantalla
 Tecla para borrar los caracteres
hacia la izquierda del la posición del cursor.
Tecla para borrar los caracteres
hacia la izquierda del la posición del cursor.


































































































































