Que es la virtualización?
La virtualización es una tecnología que permite crear
servicios de TI útiles, con recursos que están tradicionalmente
limitados al hardware. Gracias a que distribuye las funciones de
una máquina física entre varios usuarios o entornos, posibilita
el uso de toda la capacidad de la máquina.
En términos prácticos, imagínese que tiene tres servidores
físicos, cada uno con propósitos específicos. Uno es un servidor
de correo, otro es un servidor web y el tercero ejecuta
aplicaciones heredadas internas. Se utiliza alrededor del 30 %
de la capacidad de cada servidor, es decir, solo una parte de su
potencial. Pero como las aplicaciones heredadas siguen siendo
importantes para sus operaciones internas, tiene que
conservarlas junto con el tercer servidor que las aloja,
¿cierto?

Normalmente, la respuesta sería que sí. Por lo
general, era más fácil y confiable ejecutar tareas individuales
en cada servidor (es decir, un servidor, un sistema operativo y
una tarea), ya que no era sencillo asignarle varias. Sin
embargo, la virtualización permite dividir el servidor de correo
en otros dos únicos que pueden ocuparse de tareas
independientes, para poder trasladar las aplicaciones heredadas.
Se utiliza el mismo hardware, pero de manera más eficiente.

Si pensamos en la seguridad, es posible volver
a dividir el primer servidor para que gestione otra tarea y
aumentar su uso de un 30 % a un 60 %, y luego a un 90 %. Una vez
que lo logra, los servidores que quedan vacíos se pueden
reutilizar para otras tareas o retirarse todos juntos para
reducir los costos de refrigeración y mantenimiento.
¿Cómo funciona la virtualización?
El software denominado hipervisor separa los recursos físicos de
los entornos virtuales que los necesitan. Los hipervisores
pueden controlar un sistema operativo (como una computadora
portátil) o instalarse directamente en el hardware (como un
servidor), que es la forma en que la mayoría de las empresas
implementan la virtualización. Los hipervisores toman los
recursos físicos y los dividen de manera tal que los entornos
virtuales puedan usarlos.
Los recursos se dividen según las necesidades,
desde el entorno físico hasta los numerosos entornos virtuales.
Los usuarios interactúan con la informática y la ponen en
funcionamiento dentro del entorno virtual (generalmente
denominado máquina guest o máquina virtual). La máquina virtual
funciona como un archivo de datos único; por eso, tal como
ocurre con cualquier archivo digital, es posible trasladarla de
una computadora a otra, abrirla en cualquiera de ellas, y tener
la tranquilidad de que funcionará de la misma forma.

Cuando el entorno virtual se está ejecutando,
y un usuario o programa emite una instrucción que requiere
recursos adicionales del entorno físico, el hipervisor transmite
la solicitud al sistema físico y almacena los cambios en la
caché. Todo esto sucede prácticamente a la misma velocidad que
habría si este proceso se realizara dentro de la máquina física
(en especial, si la solicitud se envía a través de un hipervisor
open source diseñado a partir de la máquina virtual basada en el
kernel [KVM]).
Tipos de virtualización
Virtualización de los
datos .- Los datos que se encuentran distribuidos en
varias ubicaciones pueden consolidarse en una sola fuente. La
virtualización de los datos posibilita que las empresas los
traten como si fueran un suministro dinámico, ya que proporciona
funciones de procesamiento que permiten reunir datos de varias
fuentes, incorporar fuentes nuevas fácilmente y transformar los
datos según las necesidades de los usuarios. Las herramientas
que forman parte de este proceso interactúan con varias fuentes
de datos y permiten tratarlas como si fueran solo una. Gracias a
ello, cualquier aplicación o usuario puede obtener los datos que
necesita, de la manera que los requiere en el momento justo.
Virtualización de
escritorios .- La virtualización de escritorios suele
confundirse con la virtualización de los sistemas operativos, la
cual permite implementar muchos de estos en una sola máquina.
Sin embargo, la primera posibilita que un administrador central
o una herramienta de administración automatizada implementen
entornos simulados de escritorio en cientos de máquinas físicas
al mismo tiempo. A diferencia de los entornos de escritorio
tradicionales que se instalan, configuran y actualizan
físicamente en cada máquina, la virtualización de escritorios
permite que los administradores realicen múltiples
configuraciones, actualizaciones y controles de seguridad en
todos los escritorios virtuales.
Virtualización de los
servidores .- Los servidores son computadoras diseñadas
para procesar un gran volumen de tareas específicas de forma muy
efectiva para que otras computadoras (portátiles o de
escritorio) puedan ejecutar otros procesos. La virtualización de
un servidor, que implica dividirlo para que sus elementos puedan
utilizarse para realizar varias tareas, permite ejecutar más
funciones específicas.
Virtualización de los sistemas
operativos.- Los sistemas operativos se virtualizan en
el kernel, es decir, en sus administradores centrales de tareas.
Es una forma útil de ejecutar los entornos de Linux y Windows de
manera paralela. Las empresas también pueden insertar sistemas
operativos virtuales en las computadoras, lo cual:
Reduce los grandes gastos en sistemas de hardware, ya que las
computadoras no requieren funciones tan inmediatas.
Aumenta la seguridad porque todas las instancias virtuales se
pueden supervisar y aislar.
Limita el tiempo que se destina a los servicios de TI, como
las actualizaciones de software.
Virtualización de las
funciones de red .- La virtualización de las funciones
de red (NFV) separa las funciones clave de una red (como los
servicios de directorio, el uso compartido de archivos y la
configuración de IP) para distribuirlas entre los entornos.
Cuando las funciones del software se independizan de las
máquinas físicas donde se alojaban, las funciones específicas
pueden empaquetarse en una nueva red y asignarse a un entorno.
La virtualización de redes, que se utiliza con frecuencia en el
sector de las telecomunicaciones, reduce la cantidad de
elementos físicos (como conmutadores, enrutadores, servidores,
cables y centrales) que se necesitan para crear varias redes
independientes.
GNOME Boxes
Fue introducida en GNOME 3.4 como una solución
de virtualización sencilla y alternativa al áspero virt-manager.
Está centrada sobre todo en el escritorio y los usuarios finales
que simplemente quieren ejecutar sistemas operativos adicionales
de forma fácil y cómoda.
GNOME Boxes, que utiliza QEMU, KVM y libvirt
como tecnologías, ha ido mejorando poco a poco, y aunque en un
principio cumple su propósito de ofrecer una solución de
virtualización sencilla y amigable, quizá se muestra algo
limitada frente a competidoras como VirtualBox y VMware Player,
en parte porque estas dos últimas permiten establecer fácilmente
la red en puente y cambiar la ubicación de las máquinas
virtuales (por poner dos ejemplos sencillos). El enfoque
amigable de GNOME Boxes tiene un precio, y es que no “no
proporciona muchas de las opciones avanzadas para ajustar las
máquinas virtuales proporcionadas por virt-manager”, como bien
explica en el sitio web de la aplicación.
Boxes (cajas) es una herramienta de virtualización de
escritorio gráfica ligera que se utiliza para ver y acceder a
máquinas virtuales y sistemas remotos.
GNOME Boxes requiere que la CPU sea compatible con algún tipo de
virtualización asistida por hardware (Intel VT-x , por ejemplo);
por lo tanto, GNOME Boxes no funcionan con las CPU con
procesador Intel Pentium / Celeron ya que carecen de esta
característica.
Esta herramienta está dirigida a usuarios recién llegados a
Linux, pues Gnome boxes ha logrado eliminar demasiadas
configuraciones y cambios de configuración necesarios para
conectarse a una máquina remota o virtual.
Hay otro cliente de máquina virtual disponible en el universo
Linux, pero son complejos y, en ocasiones, están dedicados a
usuarios avanzados.
GNOME Boxes, la aplicación de código abierto y gratuito, hace
que sea muy fácil conectarse a máquinas virtuales remotas
simplificando los pasos. Estas son algunas de sus
características únicas.
Aplicación nativa de GNOME con interfaz de
usuario amigable
Fácil acceso a máquinas virtuales
Monitor de rendimiento
Crear VM desde archivos, URL remota
Fácil acceso
A diferencia de virt-viewer y remote-viewer, Boxes permite ver
máquinas virtuales invitadas, pero también crearlas y
configurar, de forma similar a virt-manager. Sin embargo, en
comparación con virt-manager, Boxes ofrece menos opciones y
funciones de administración, pero es más fácil de usar.
Antes de proseguir si queremos instala un SO,
debemos tener su imagen ISO, del sistema que queremos
virtualizar, a su consideranción consigan su SO que les interese
o quieran probar, descargarlo de algún sitio, de confianza, y
los pueden dejar en el directorio Descargas.
Instalación de Gnome Box
Para instalar Gnome boxes use la tienda
Software esta en Flatpack, pero no tiene soporte para medios de
USB, pero se ha incluidos una herramienta que sustituye y por
mucho las versiones anteriores, puede acceder a los
directorios del SO, y copiarlos a la máquina virtual.

A continuación se mostrara la ventana
principal y hacemos clic en el icono que tiene forma de lupa
(arriba a la izquierda)

en el cuadro de búsqueda escribimos cajas, y
desplazamos la lista hasta localizar Cajas Virtualización
sencilla, y clic sobre esta descripción

Use el botón Instalar, y al finalizar veras lo
siguiente, desde flatpak, también desde snap, pero en flatpak
tiene un sevicio adicional que veremos adealante:

para iniciar la instalación te solicitara autorización del
Administrador (root)

Comenzará la instalación
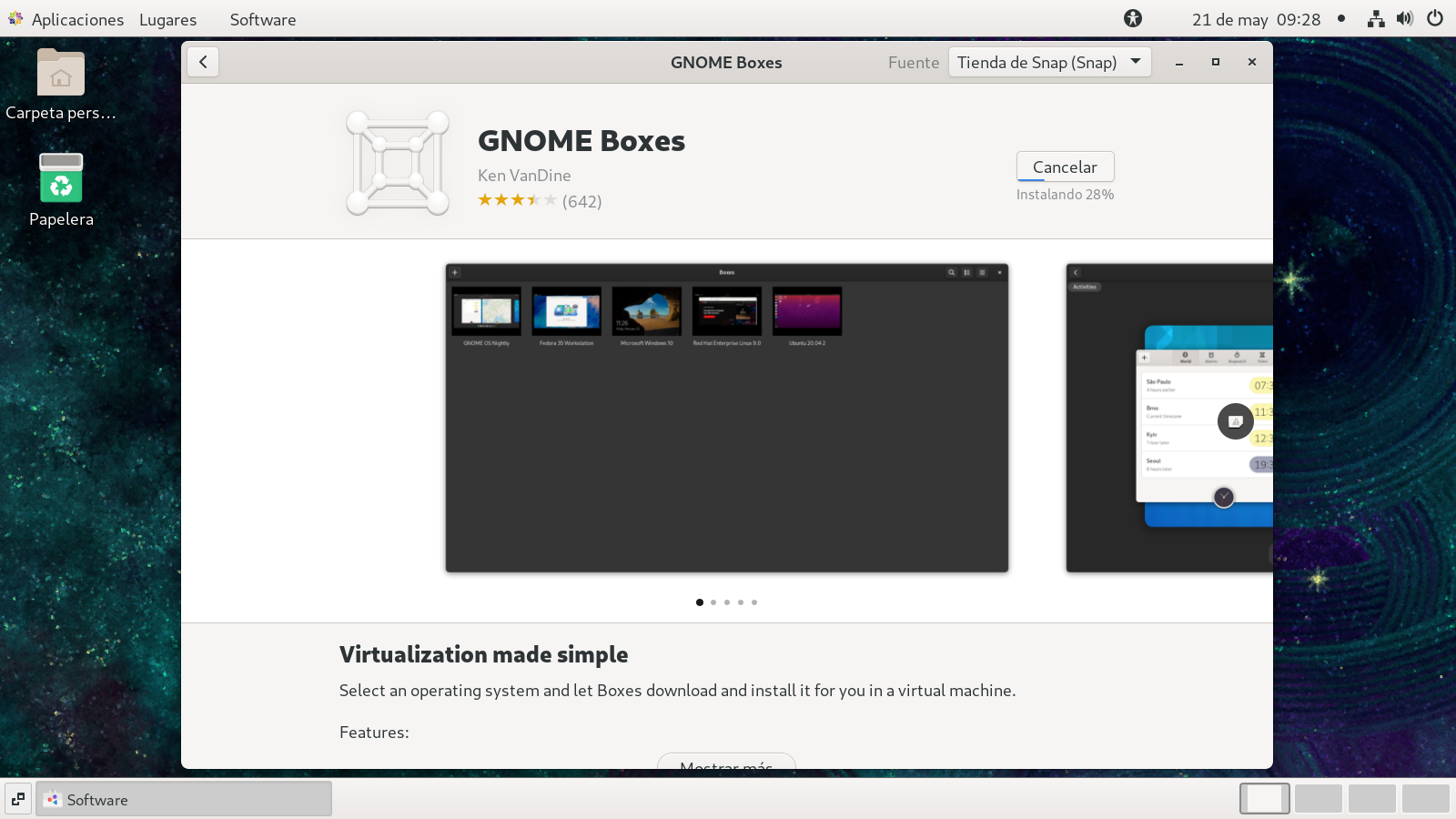
al terminar la instalación:

cerramos la tienda software
En aplicaciones y Herramientas del sistema
encontramos a Cajas (Gnome Boxes), podemos usarlo directamente,
primero usaremos el Gestor de Máquinas virtuales, la ventaja de
este es que podemos controlar mas aspectos de la virtualización
del SO a usar, para ajustarlo mas a lo que pretendemos usar o
instalar un SO, espacio de disco, memoria RAM, procesadores a
usar, etc.
Virtualización con Gestor de máquinas
virtuales
en esta aplicación requiere mucha memoria del
sistema minimo 12 GiB de RAM, se puede instalar pero no aseguro
que funcione adecuadamente, aquí es muy
probable que se "cuelge" el equipo completo, usar con
precaución.
Para la siguiente aplicacion
es necesario asegurarnos de instalar los siguientes paquetes a
CentOS stream 9 (son para agregar
servicios a la virtualización de Gnome Boxes, instalado
previamente, es posible que algunos de ellos ya estén
instalados pero realizamos esto para asegurarnos):
dnf install
--nogpgcheck spice*
dnf install --nogpgcheck gnome-common gcc gcc-c++ automake
autoconf libtool
dnf install --nogpgcheck spice-*
dnf install --nogpgcheck virt-manager
dnf install --nogpgcheck virt-viewer
El siguiente paquete es muy importante para
proporcionar permisos a Gnome Boxes, en una terminal como su
-, escriba lo siguiente, es cuando decidamos instalar
gnome-boxes desde flatpak :
flatpak install flathub
com.github.tchx84.Flatseal
nos solicitara confirmación para la instalación, a lo que
contestamos Y/Si, se solicita en 2 ocasiones para la
instalación:
[root@alienware-centos9 ~]# flatpak install flathub
com.github.tchx84.Flatseal
Buscando coincidencias…
com.github.tchx84.Flatseal permisos:
ipc
fallback-x11
wayland
x11
dri file
access [1] dbus access [2]
[1] /var/lib/flatpak/app:ro,
xdg-data/flatpak/app:ro,
xdg-data/flatpak/overrides:create
[2]
org.freedesktop.impl.portal.PermissionStore, org.gnome.Software
ID
Rama Op Remoto Descarga
1. [✓] com.github.tchx84.Flatseal stable
i flathub 124.9 kB / 151.8 kB
Instalación completada.
necesitamos crear un directorio donde permitir el intercambio
de archivos entre MV, y el SO local, por mi cuenta he
creado un directorio llamado intercambio:
abre la terminal y realizas esto: (como usuario)
mkdir
/home/msantos/Desacragas/intercambio
(msantos es mi usuario, tu cambialo por el que tu generaste)
Ahora que ya tenemos nuestro directorio para intercambio, y ya
tenemos nuestro flatseal, (Aplicaciones, Accesorios, Flatseal)
que usaremos para configurar Gnome Boxes (cajas), y permitir
acceso a archivos desde la máquina virtual a LINUX, Centos
Stream 9, y pasarlos a la máquina virtual

al ingresar, del lado izquierdo hay un panel donde estan las
aplicaciones instaladas desde Flatpack, seleciona la de Gnome
Boxes.

y del lado derecho, desplazarte hasta la
sección Filesystem, y en Otros Archivos agrega la ruta creado
para intercambio de archivos, los triangulos azules indica que
el usuario agrego estos valores, al final /:rw significa que es
un directorio de lectura y escritura (puedes o no colocar esta
propiedad)

Solo cerramos la aplicación y quedara
registrado el cambio, y esto permitiría el intercambio de
archivos, esto funciona bien para distribuciones en LINUX, para
windows, se requiere un programa adicional, y se requiere un
programa en windows para permitirlo, mas adelante les decimos
como.
Ya teniendo un ISO preperado de un SO (el que tu quieras
virtualizar ejem Windows, que si lo utilizaras posteriormente,
hay que registrarlo)
Gnome Boxes (cajas),
Iniciamos en Aplicaciones -> Herramientas del Sistema ->
Cajas

Iniciamos con la aplicación y seleccionamos el botón Nueva
(Nueva máquina virtual) El signo + arriba a la izquierda

Seleccionamos Instalar desde un archivo

Seleccionamos la imagen ISO del sistema a instalar, del
directorio que esta disponible, en este caso Windows 10.

Seleccionamos la imagen ISO, y clic en el botón Abrir
y nos presenta la ventana, donde informa la configuración que
detecto, si no coincide podemos cambiar la información del
instalación:

En Sistema operativo hacemos clic, y en algunos casos
presentara un cuadro donde dice mostrar sistema operativos
pasados, y ahi selecionamos Microsoft Windows 10

Se establecen los parámetros para la creación de la
virtualizacion, de forma automática pero podemos asignar mas
recursos a este sistema, usando los botones para asignar los
recursos.
Ya establecidos Clic en Crear

Comienza la instalación tradicional en windows, sigue los
pasos para su instalación.
Al terminar la instalación procedemos a la ejecución de la
máquina virtual, a todo esto el directorio donde almacenan las
instalaciones de los SO es:
/home/usuario_nombre/.var/app/org.gnome.Boxes/data/gnome-boxes/images
Ejecucion de las maquinas virtuales
Para ejecutar los SO virtualizados solo
hacemos clic sobre el espacio que corresponde al SO, por
ejemplo un Windows 10:
ya iniciado el sistema, instalamos Goggle Chrome (no se
explica la instalación en este punto, ya que es bien sabido como
es)
y necesitamos descargar de internet el archivo
spice-guest-tools-latest.exe, que es necesario para comunicar
Windows con LINUX, use el siguiente enlace desde la pagina, esta
al final:
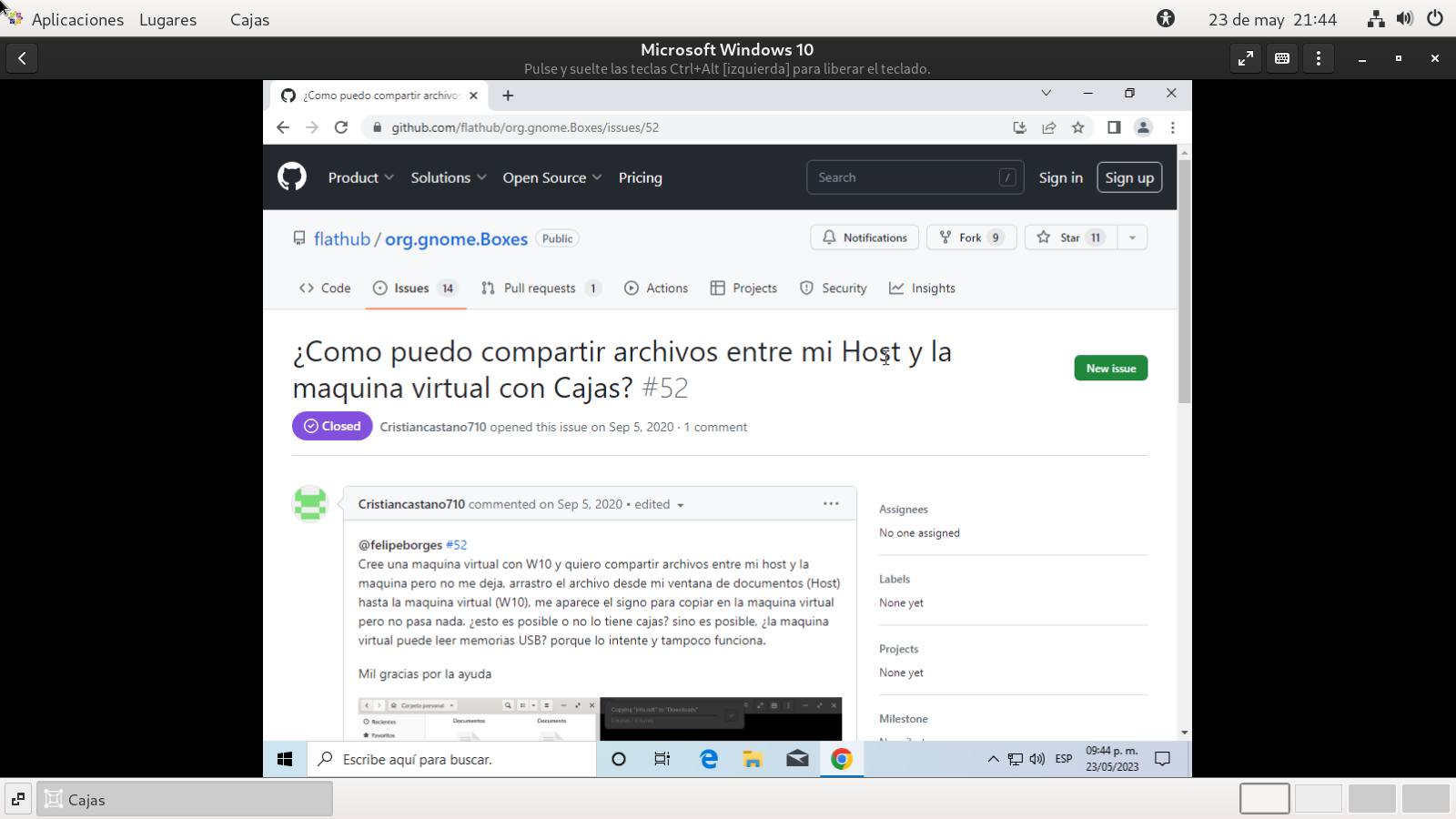

el enlace se encuentra en el URL de color azul, descargando el
programa, lo ejecutamos como Administrador:

y el proceso de instalación se ve aquí:


antes de terminar la instalación el área de la pantalla de
windows se expande a toda la área la pantalla

podemos agregar programas en esta máquina
virtual, usando el directorio creado para este propósito
intercambio, copiamos el programa o ISO, a ese del directorio, y
en estando en Cajas hacemos clic sobre el icono que tiene 3
puntos en vertical, que esta arriba a la derecha y nos mostrara
una lista seleccionamos la primera opción de la lista, Enviar
archivo... con ello nos llevara al SO de Centos stream
9, y seleccionamos el directorio donde copiamos el ISO, o
programa que nos interese.

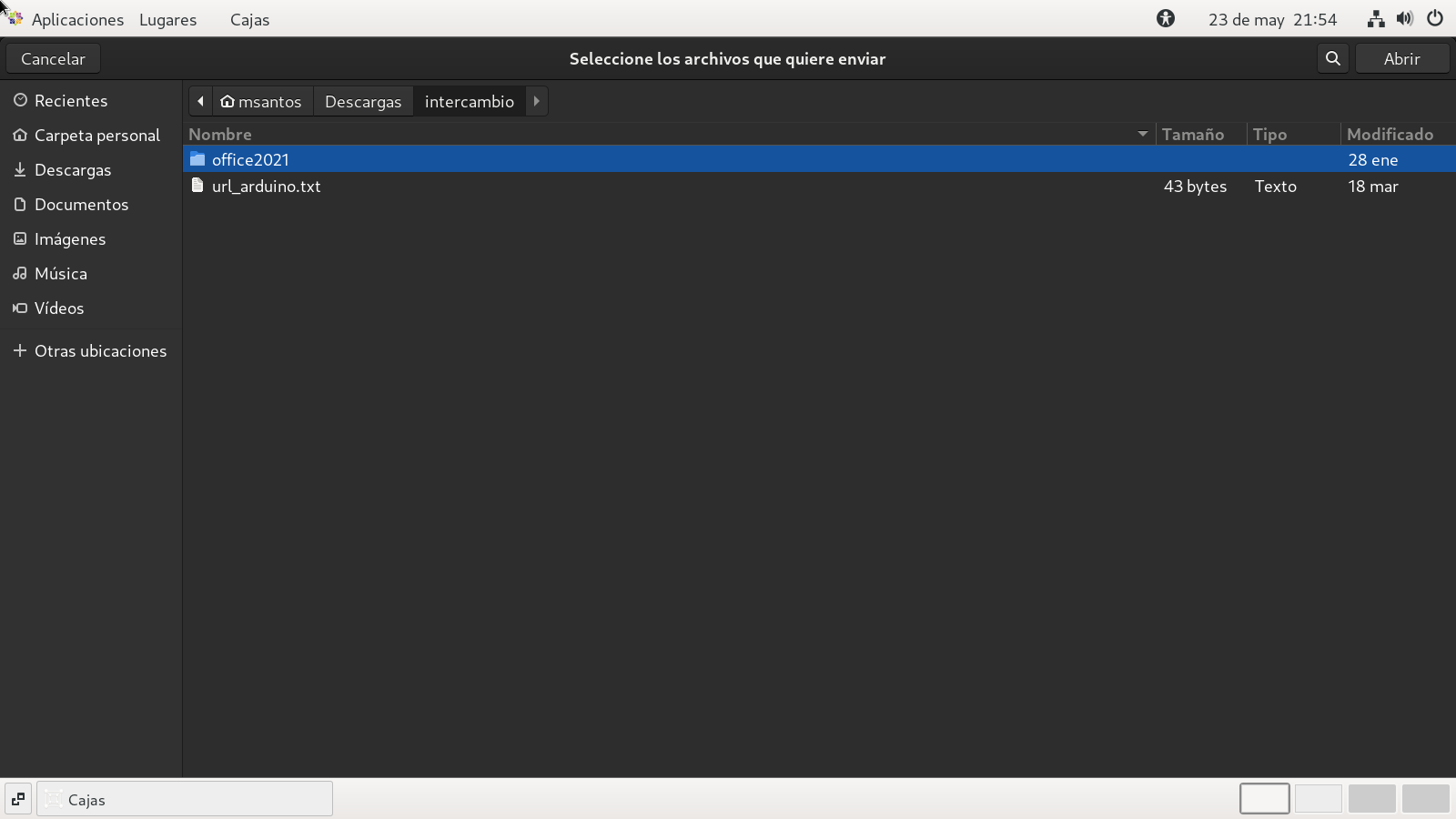

comenzara la copia entre el SO LINUX y windowze.
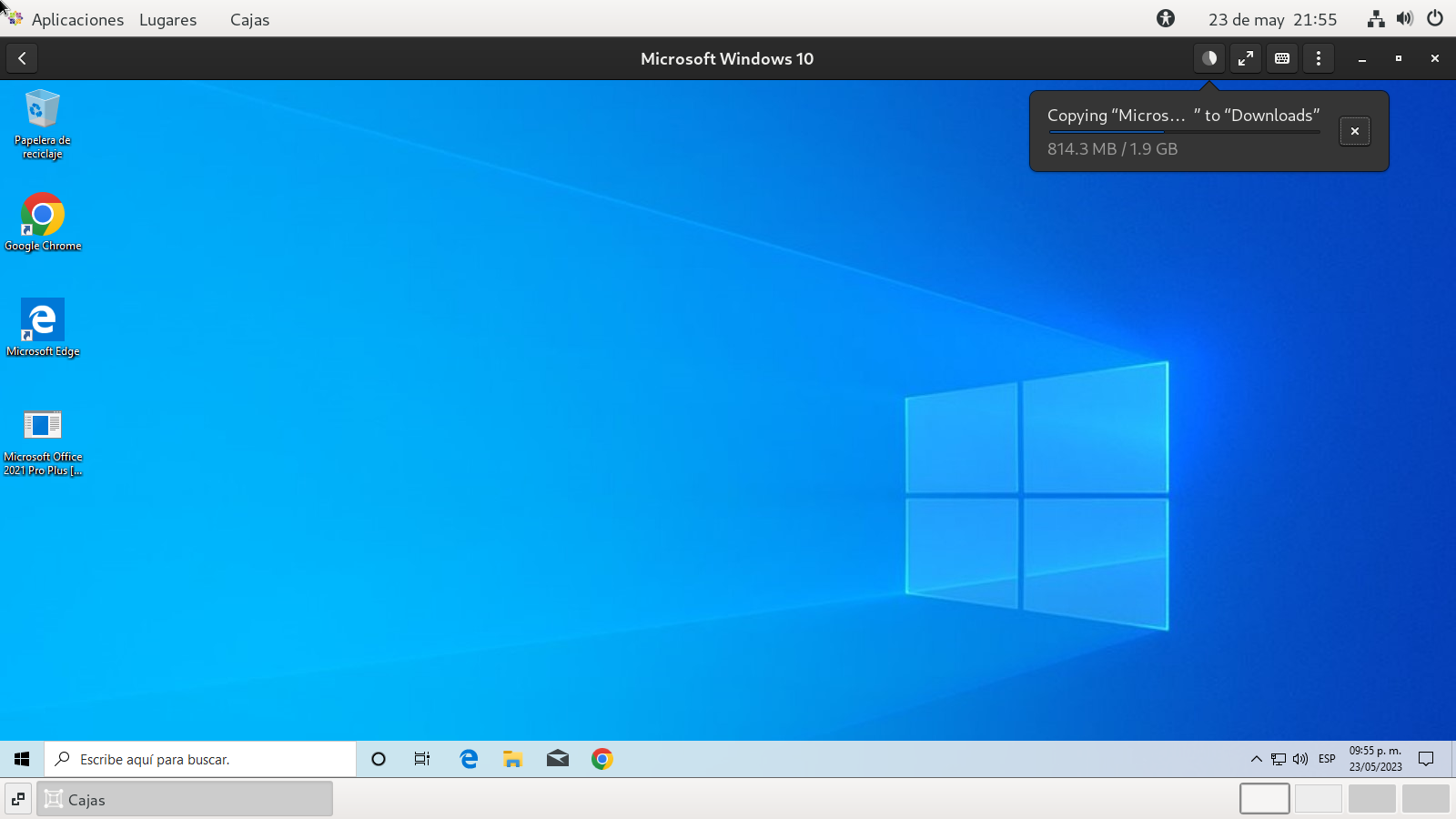

generalmente se descarga en el escritorio,
pasemos el programa a otro sitio adecuado para la
instalación, o ejecución de este.
El empleo de Qemu, KVM, y libvirt. Trasfieren
un comportamiento muy bueno en la máquina virtual, la cual
actual al margen del Kernel utilizado en nuestro PC.
Olvidándonos de los problemas originados por usar el más
actualizado y la contrariedad con el módulo DKMS que se origina
a menudo en VirtualBox.
Porque usar las VM ?
Probar fácilmente nuevos
sistemas operativos
Probar sistemas operativos es la razón más
socorrida para usar máquinas virtuales. Como ya hemos contado,
hay soluciones que lo ponen muy fácil para ponerlas en
funcionamiento y así explorar lo que hay más allá de lo
instalado en la máquina anfitriona, que por lo general suele ser
Windows.
Lo de probar sistemas operativos puede motivarse en la mera
curiosidad, las ganas de conocer las características o las
novedades de cada nuevo lanzamiento sin poner en riesgo la
máquina real o las intenciones de llevar a cabo una posible
migración debido a que el ordenador utilizado no cumple con los
exigentes requisitos de Windows 11 por ejemplo.
Realizar pruebas sin
dañar el sistema anfitrión
Otra razón para usar máquinas virtuales es la
realización de pruebas sin dañar el sistemas anfitrión. Dicho
con otras palabras, en lugar de ejecutar un sistema operativo
distinto, se emplearía el mismo que el de la máquina real para
así llevar a cabo pruebas que, en caso de salir bien, podrían
trasladarse al sistema anfitrión.
Mantener vivos sistemas operativos
obsoletos
¿Tienes alguna aplicación fundamental para ti
pero que solo funciona en un sistema operativo que se ha quedado
sin soporte? Aquí las máquinas virtuales son una muy buena
solución porque no solo permiten mantener dicha aplicación en
funcionamiento, sino que además proporcionan aislamiento para
evitar catástrofes a nivel de seguridad (aunque esto depende de
una correcta configuración de la propia máquina virtual). En
caso de depender de una aplicación que solo funciona sobre
Windows XP, sería muy recomendable trasladar la producción a una
máquina virtual.
Cloud es una forma de tener servidores en internet sin tener
grandes gastos, pero dependera de la cantidad de solicitudes y/o
uso del servidor en el cloud ya sea en aws o google cloud, y eso
dependera de los costos asociados a esto. Para comprender esto
mejor te sugiero ver esto.
AWS
AWS
de Amazon
Amazon Web Services
(AWS) es la plataforma en la nube más adoptada y completa en
el mundo, que ofrece más de 200 servicios integrales de
centros de datos a nivel global. Millones de clientes,
incluso las empresas emergentes que crecen más rápido, las
compañías más grandes y los organismos gubernamentales
líderes, están usando AWS para reducir los costos, aumentar
su agilidad e innovar de forma más rápida.
Mayor funcionalidad
AWS cuenta con una
cantidad de servicios y de características incluidas en
ellos que supera la de cualquier otro proveedor de la nube,
ofreciendo desde tecnologías de infraestructura como
cómputo, almacenamiento y bases de datos hasta tecnologías
emergentes como aprendizaje automático e inteligencia
artificial, lagos de datos y análisis e internet de las cosas.
Esto hace que llevar las aplicaciones existentes a la nube
sea más rápido, fácil y rentable y permite crear casi
cualquier cosa que se pueda imaginar.
AWS también tiene la funcionalidad más
completa dentro de esos servicios. Por ejemplo, AWS ofrece
la más amplia variedad de bases de datos que están diseñadas
especialmente para diferentes tipos de aplicaciones, de modo
que usted puede elegir la herramienta adecuada para el
trabajo a fin de obtener el mejor costo y rendimiento.
Aqui la forma de registrarse una
cuenta en AWS de forma gratuita
ingresamos por google y buscamos aws,
y accedemos al link mostrado Amazon Web Services:
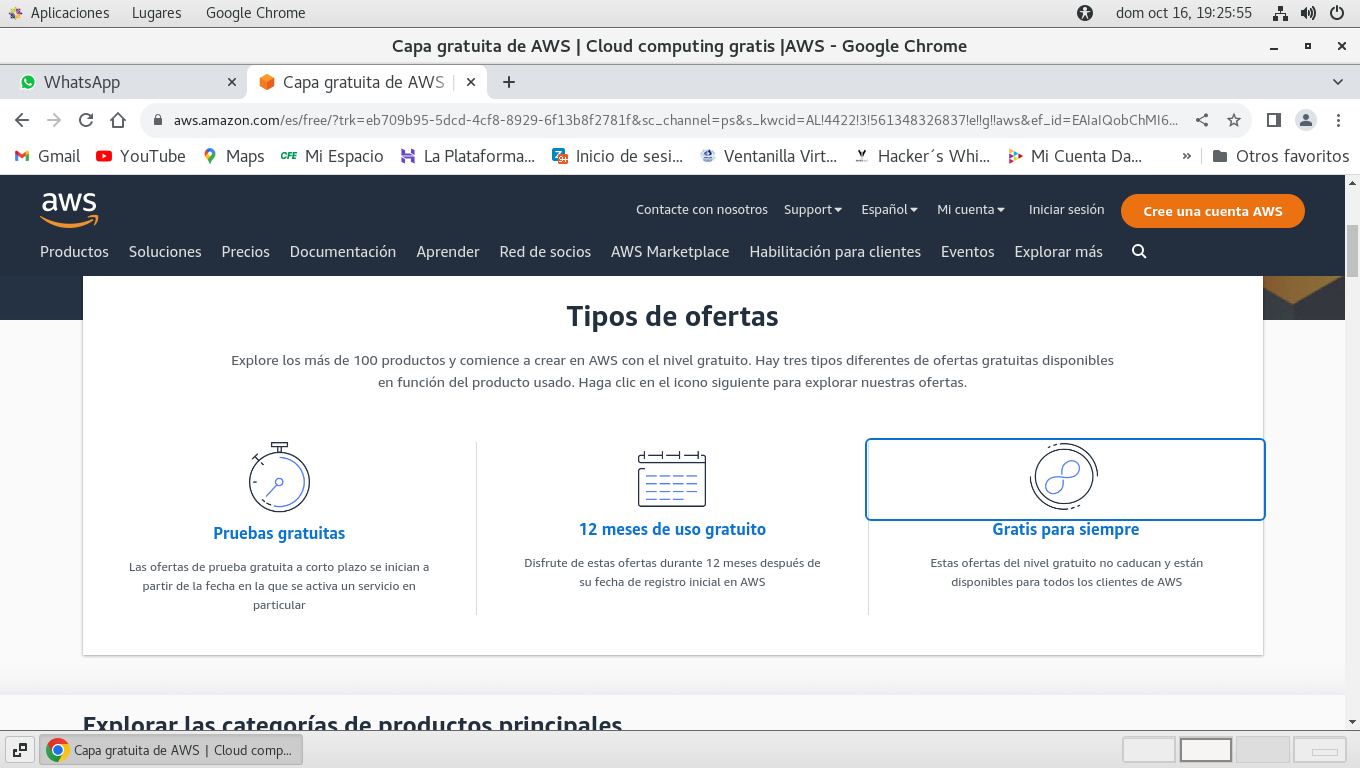
Seleccionamos la oferta que nos
ayude a usar AWS, yo he seleccionado Gratis para Siempre
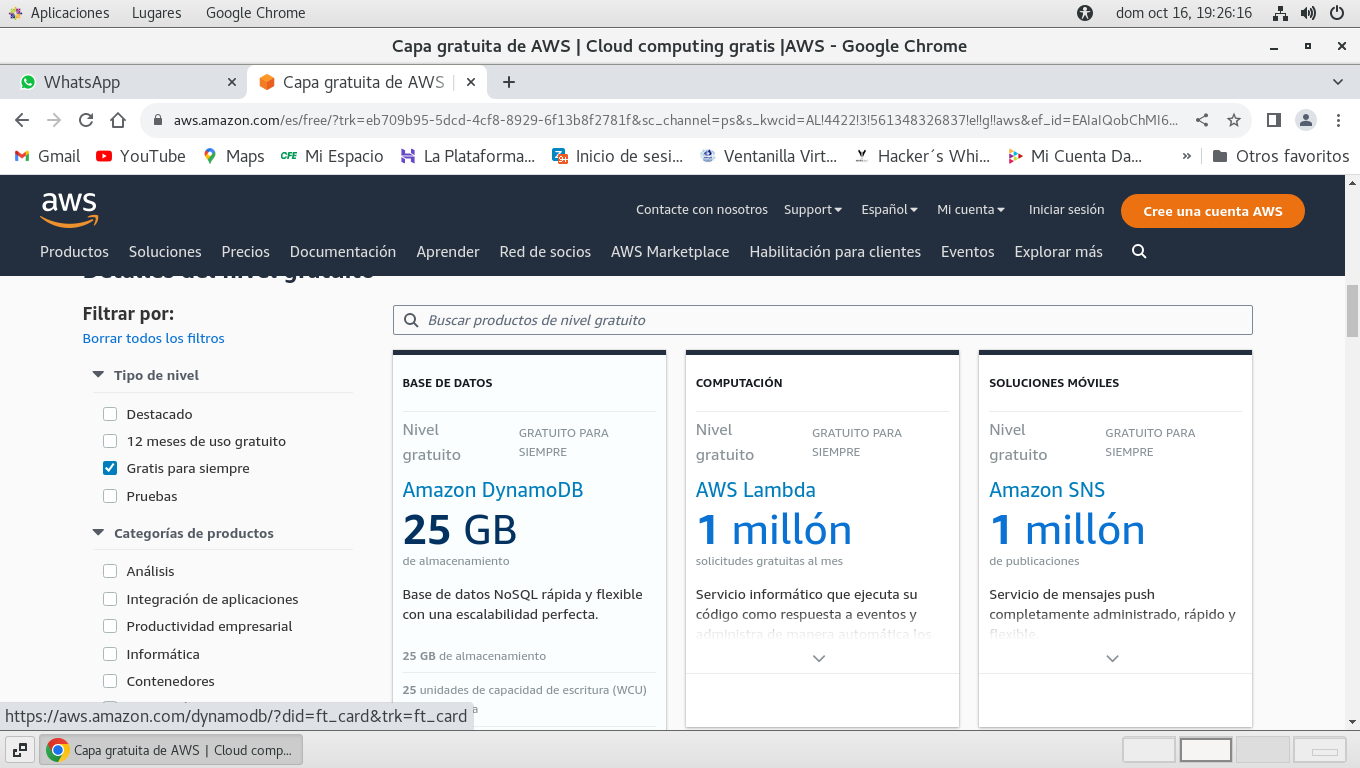
Hay varias categorías yo seleccione
AWS Lambda para 1 millón de solicitudes diarias (Gratuito
para siempre)
En esta oferta esta lo siguiente,
seleccione Crear una cuenta de AWS
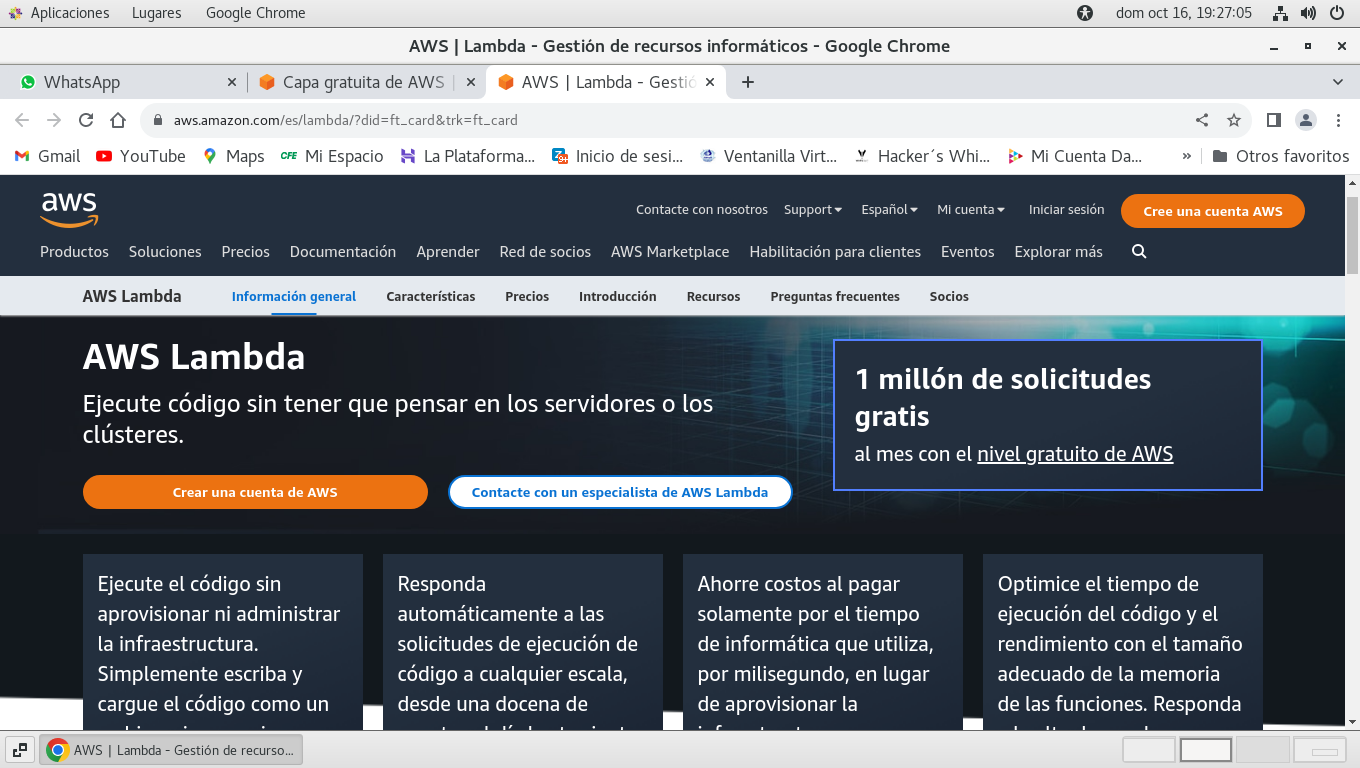
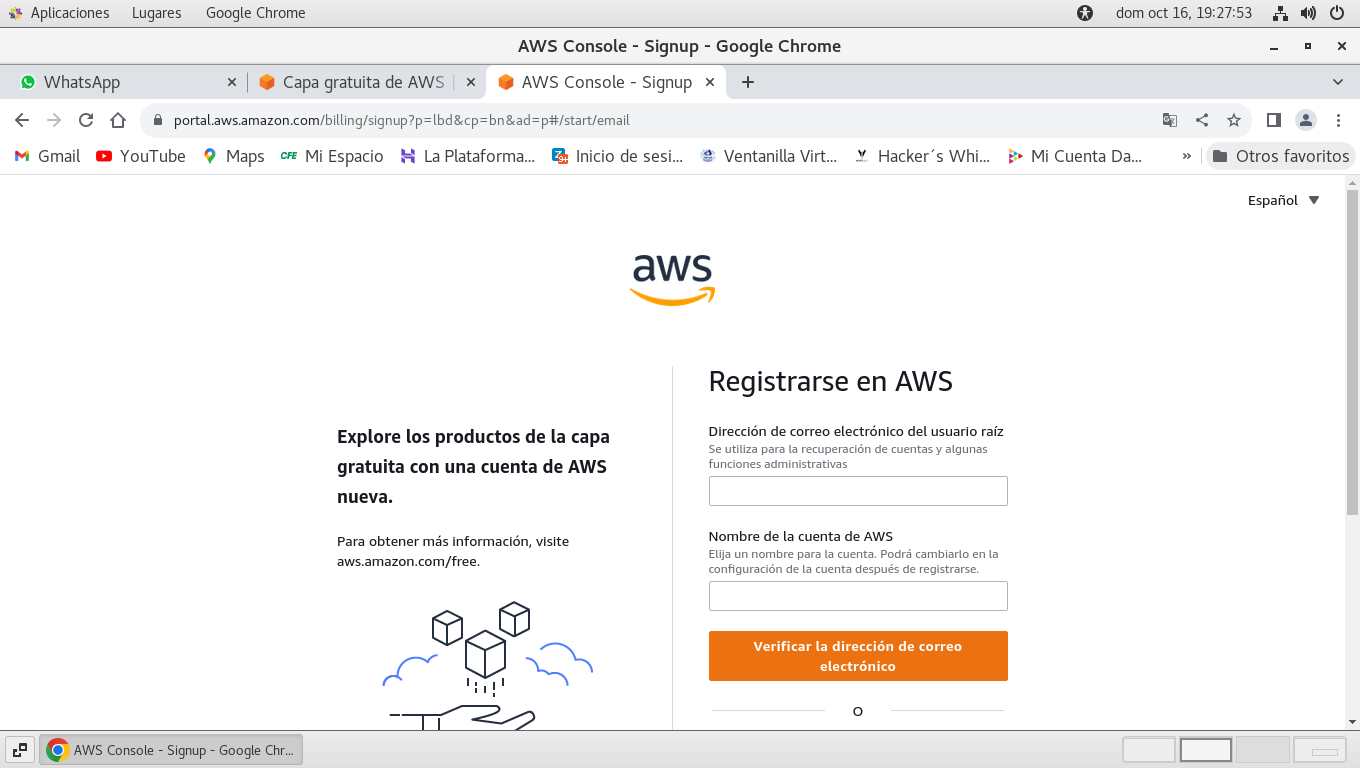
a continuación solicita un correo
electrónico, y un nombre de cuenta, y realiza una
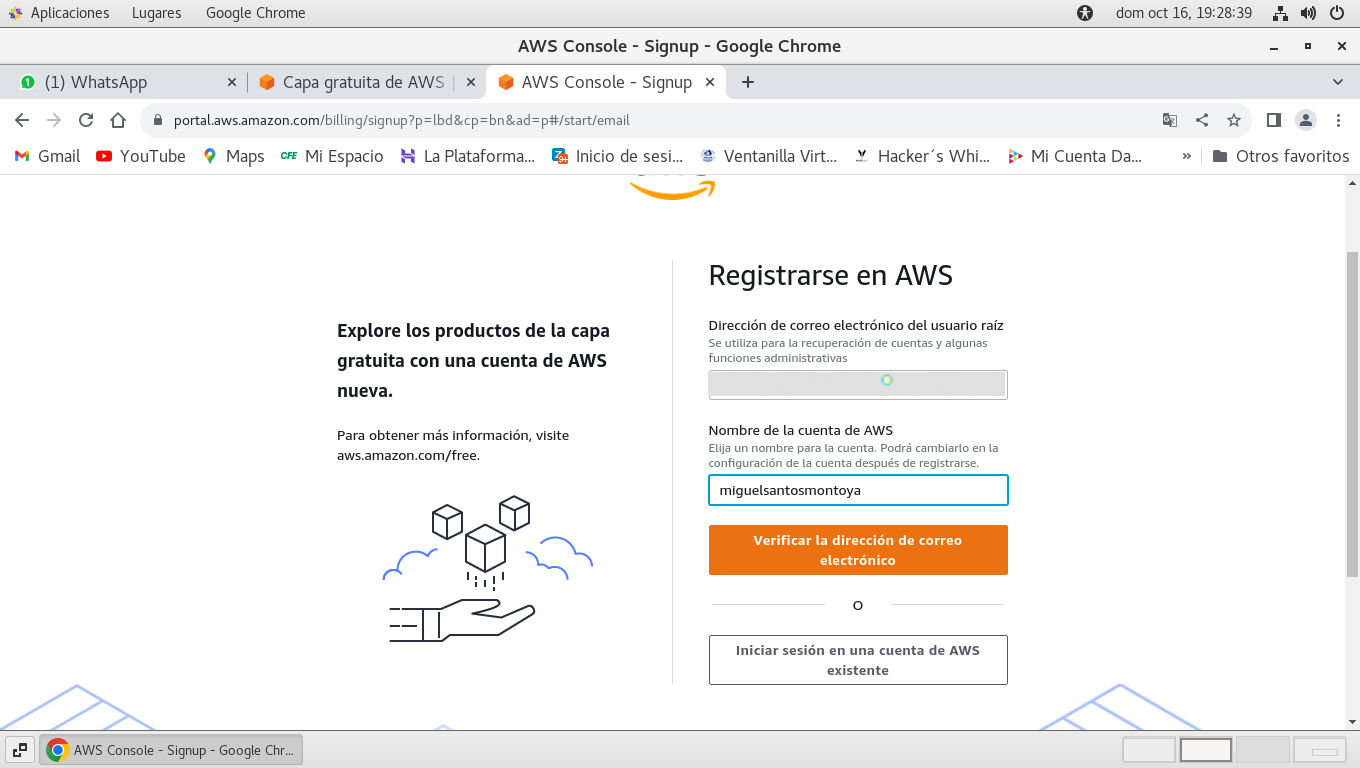
verificación que esto no sea fraudulento:
se procede con la verificación del
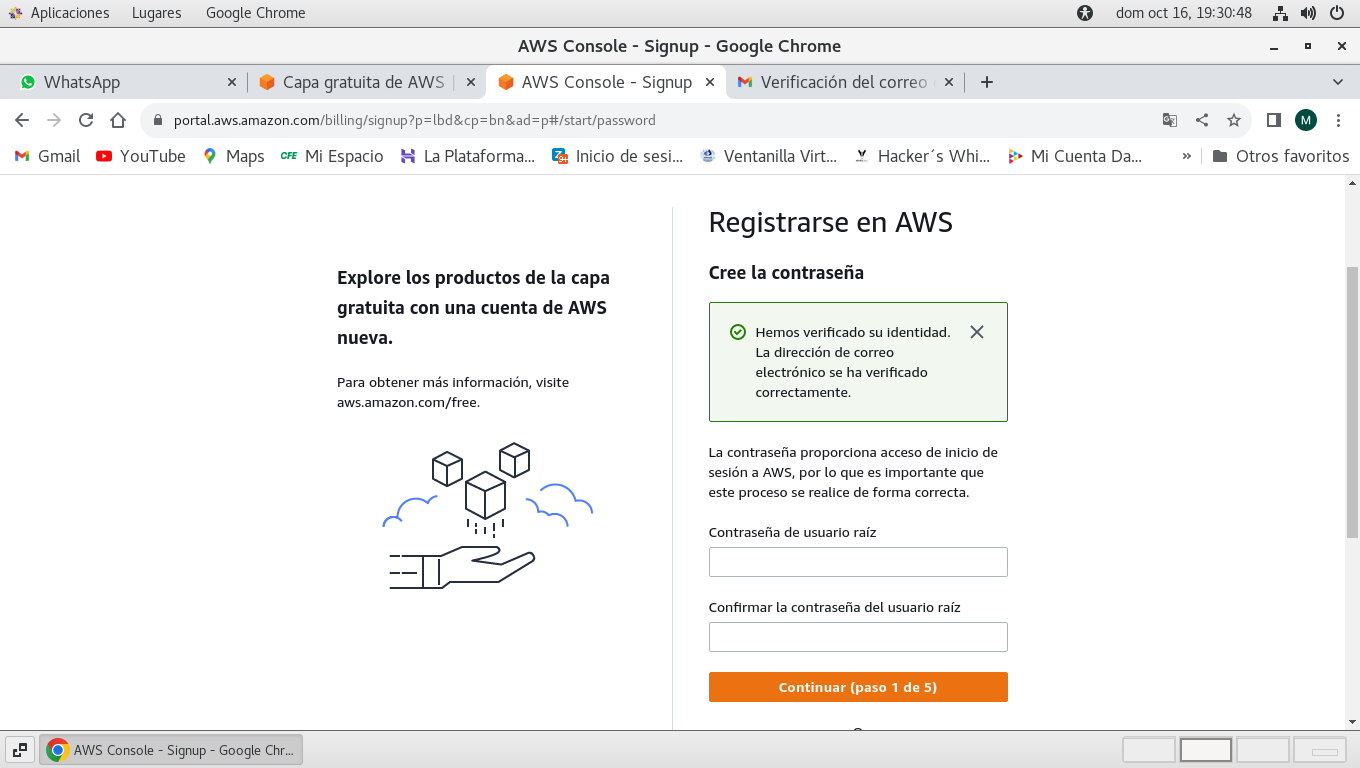
correo:
Al correo asignado se enviá un código
que se escribe en un campo del formulario, y este es
autentificado, donde si es correcto todo pasa a esta
pantalla que se muestra, y ahora debemos de establecer una
contraseña para acceso al servicio de AWS. Continuamos al
siguiente paso en el botón color naranja.
selección de : Personal: para sus
propios proyectos
mas datos
solicita tarjeta de crédito o débito
para confirmar que es una persona mayor de 18 para su
confirmación no hay cargo
verifica datos de tarjeta (no hay
cargos)
confirmación del teléfono y clave ce
comprobación de seguridad
seleccionamos el plan de soporte:
Basic: gratis
finalizando

al correo registrado llega esto, son
tutoriales para familiarizarse en los servicios:
para iniciar sesión
promocionamos el correo con que nos
registramos:
contraseña
ya estamos listos para comenzar
en la parte inferior de la pagina:
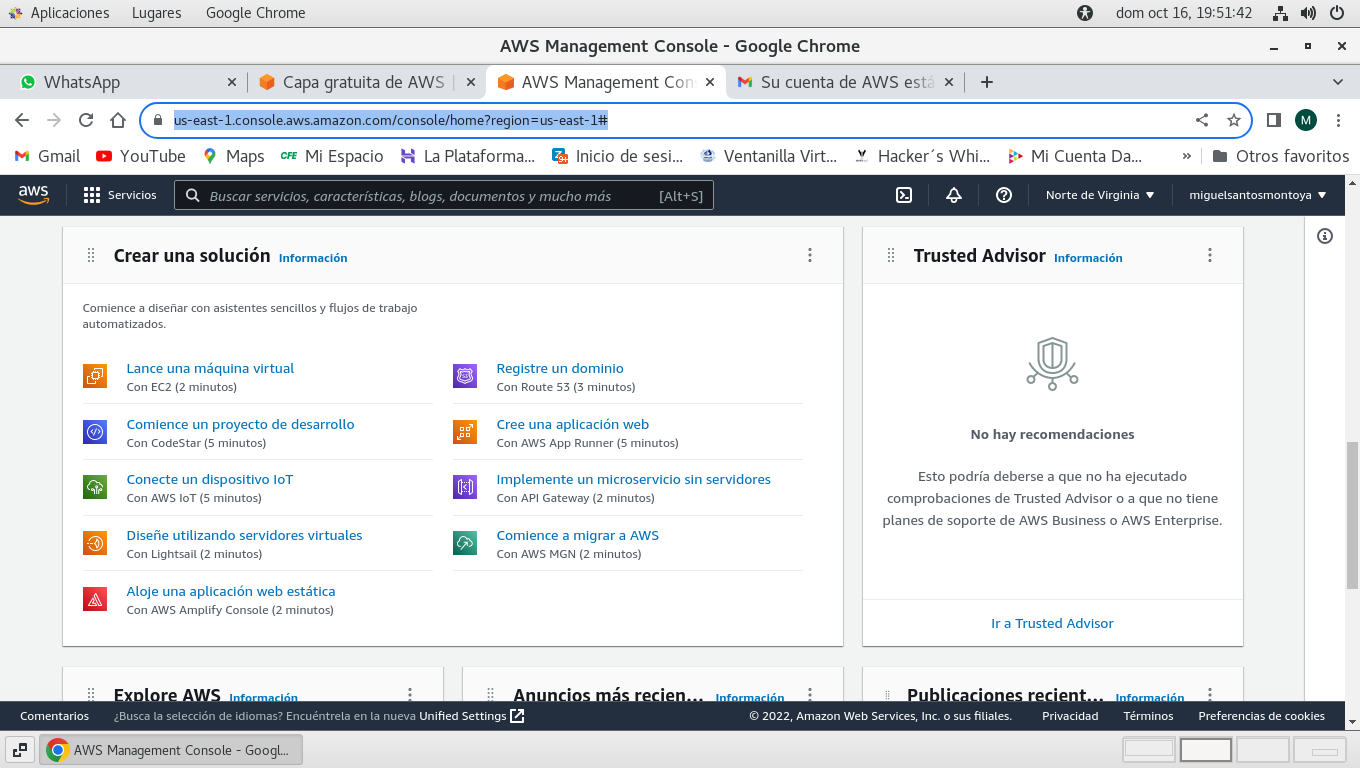
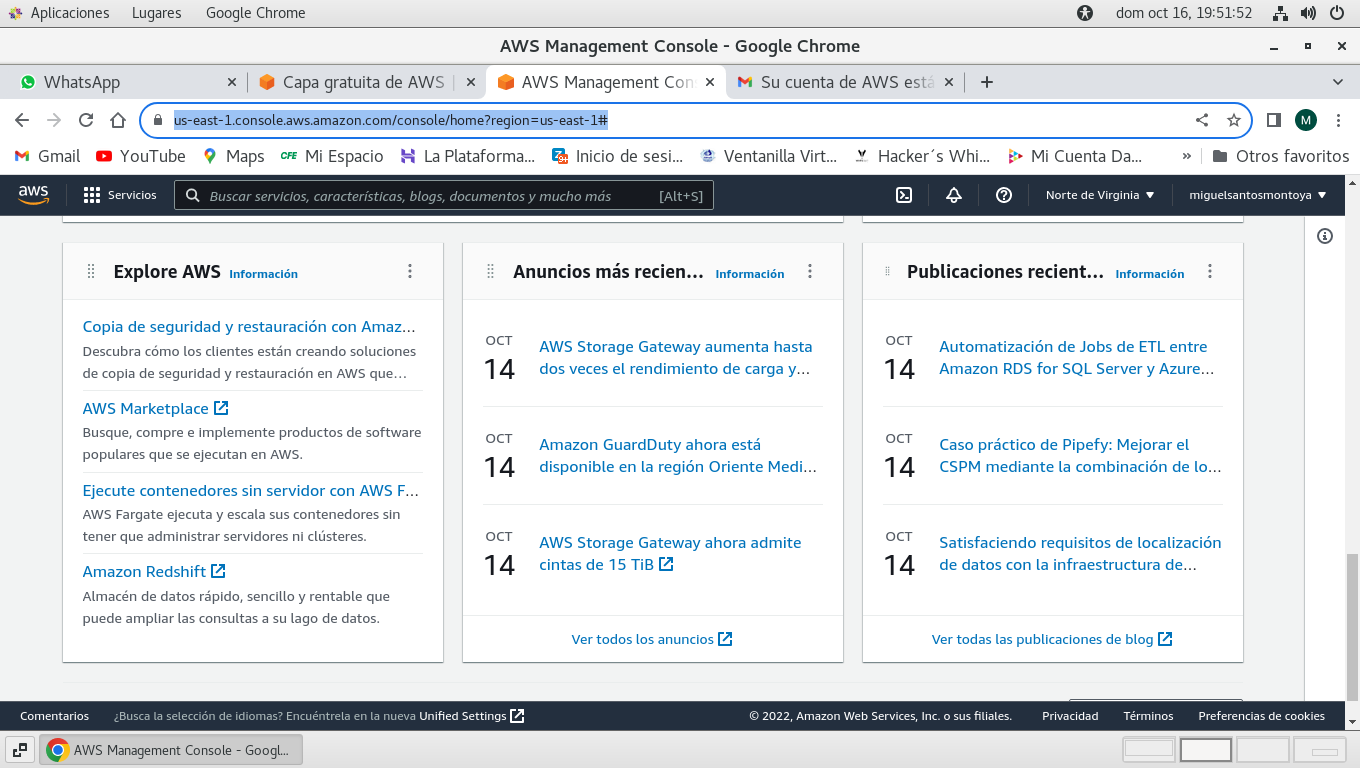
para iniciar una maquina virtual
tenemos, iniciando en la consola de aws (Your AWS Console):
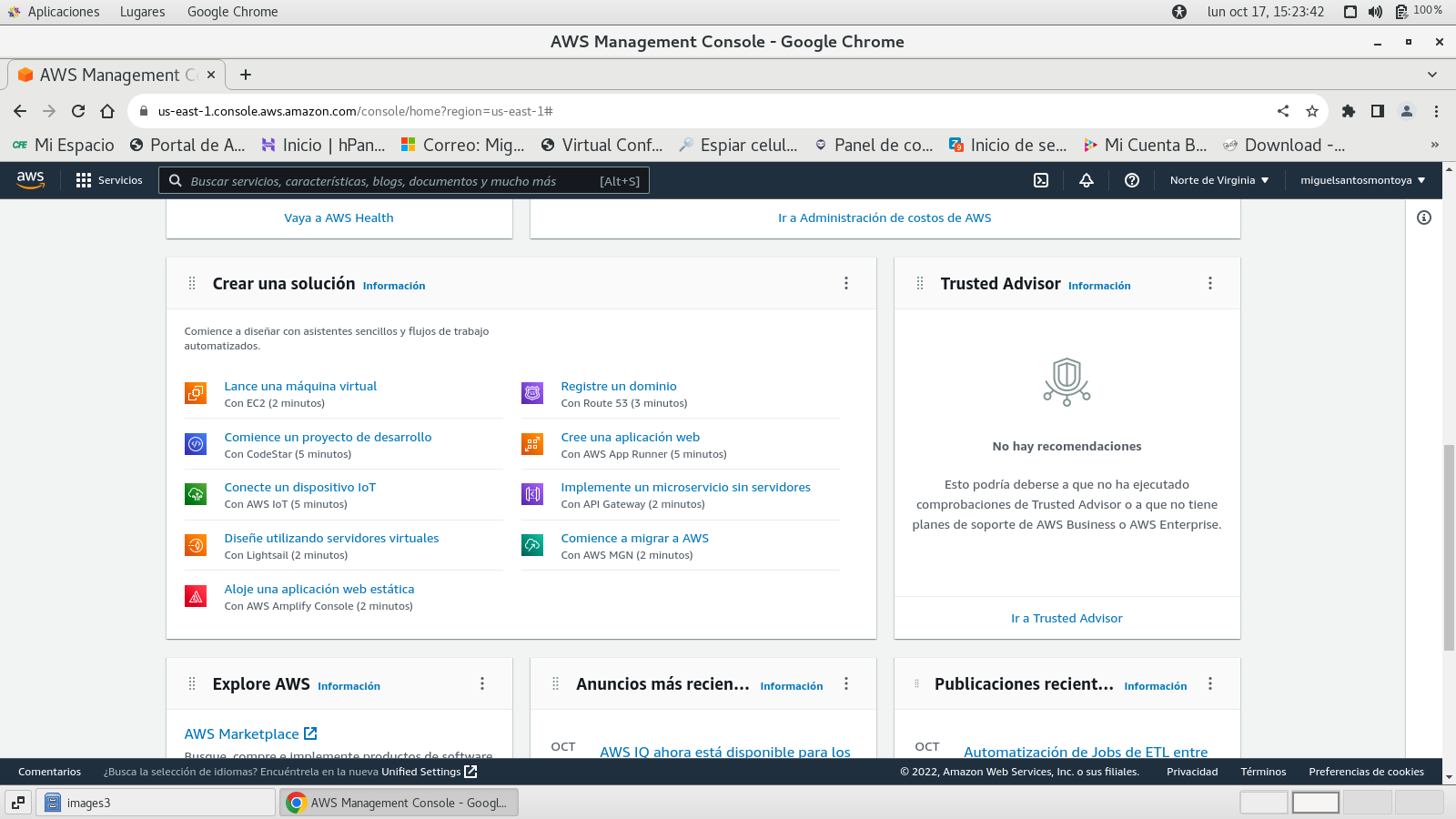
desplazando hacia abajo encontramos
(Crear una solución) con los tiempos aproximados de
realización, tomamos : Lance una maquina virtual
Lanzar una instancia, asignamos un
nombre al servidor que queremos usar
seleccionamos un SO para ser
virtualizado
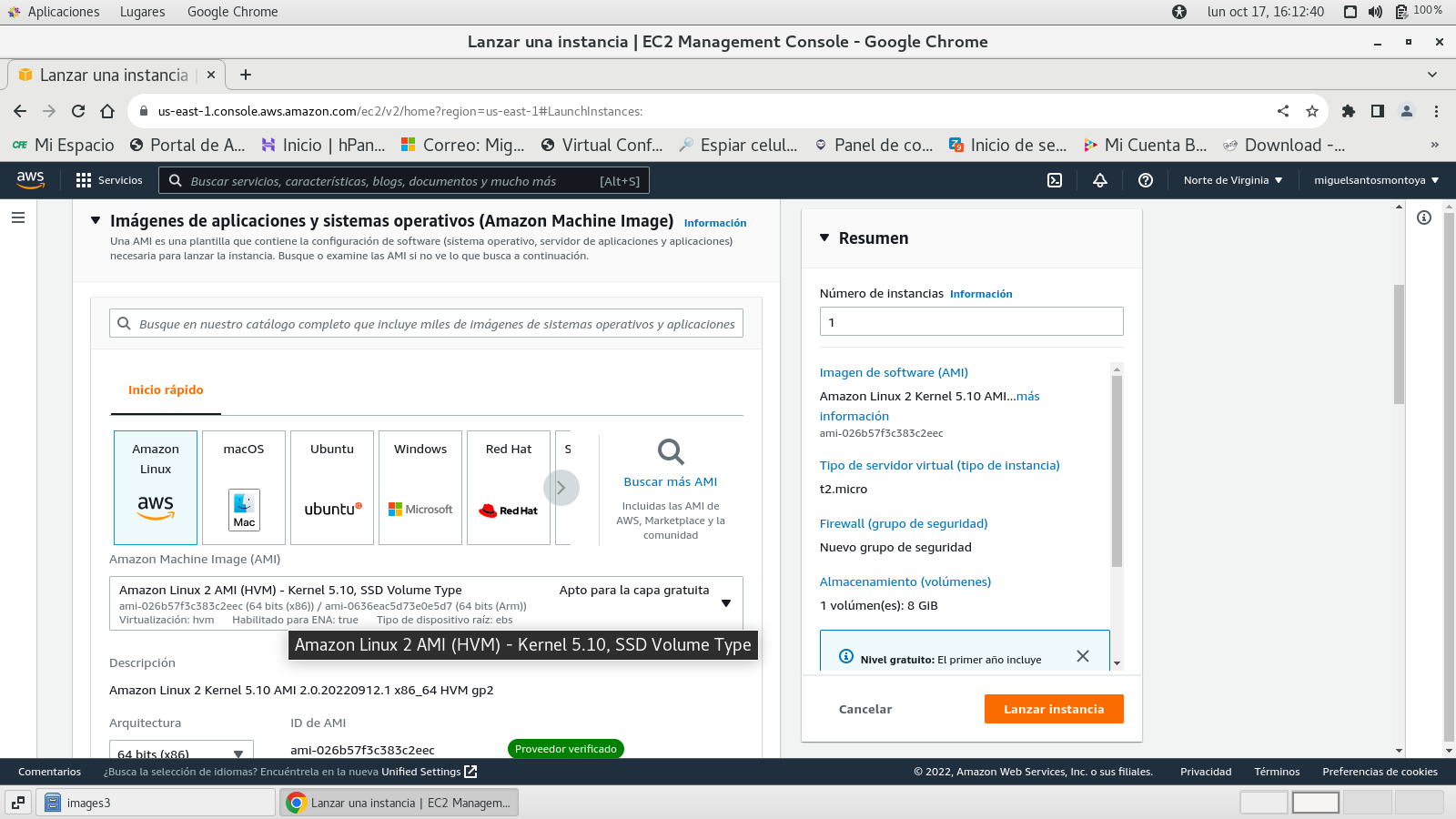
Selecciono en este caso RED-HAT
Ahora seleccionamos el tipo de
Instancia (cantidad de procesadores y memoria) y las claves
para inicio de sesión.
Crear un nuevo par de claves se genera un archivo del tipo .pem y se
debe de almacenar en el disco de tu computadora en un
directorio especifico, que no lo olvides.
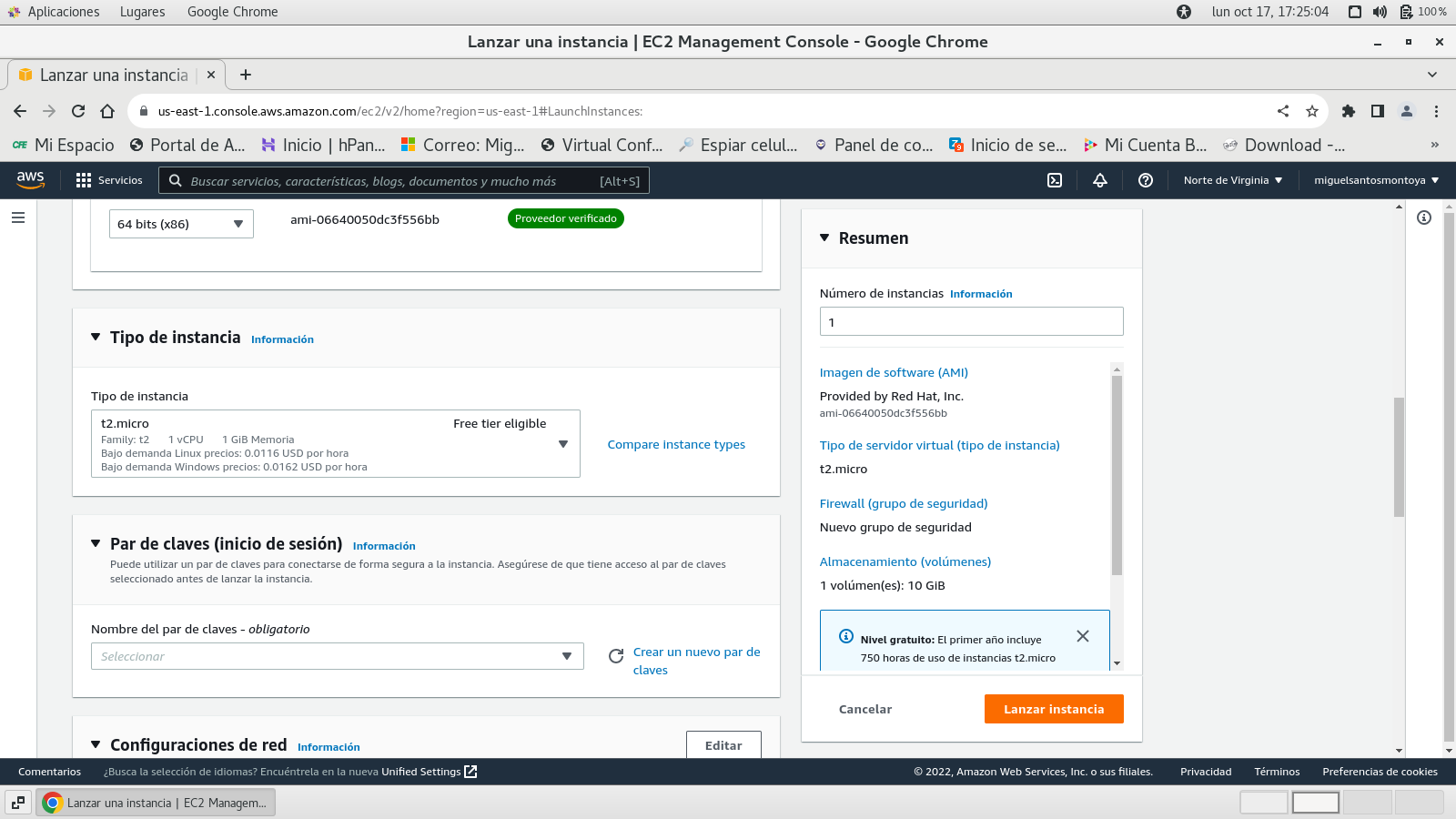
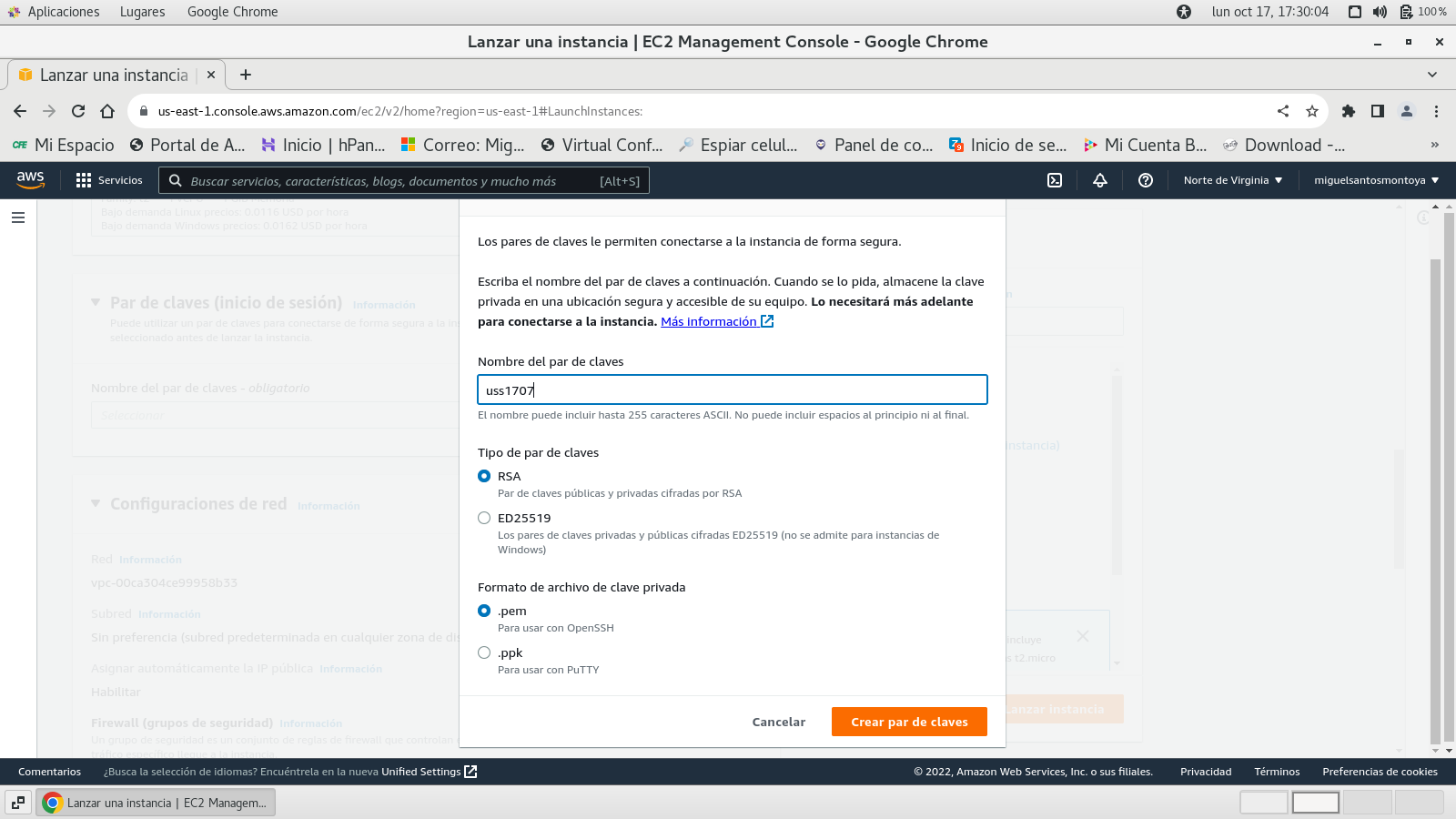
se genera la clave .pem (para ser
usado con ssh este lo revisamos en la unidad anterior)
Configuación de red
almacenamiento (podemos dejarlo de esa
manera)
y detalles avanzados
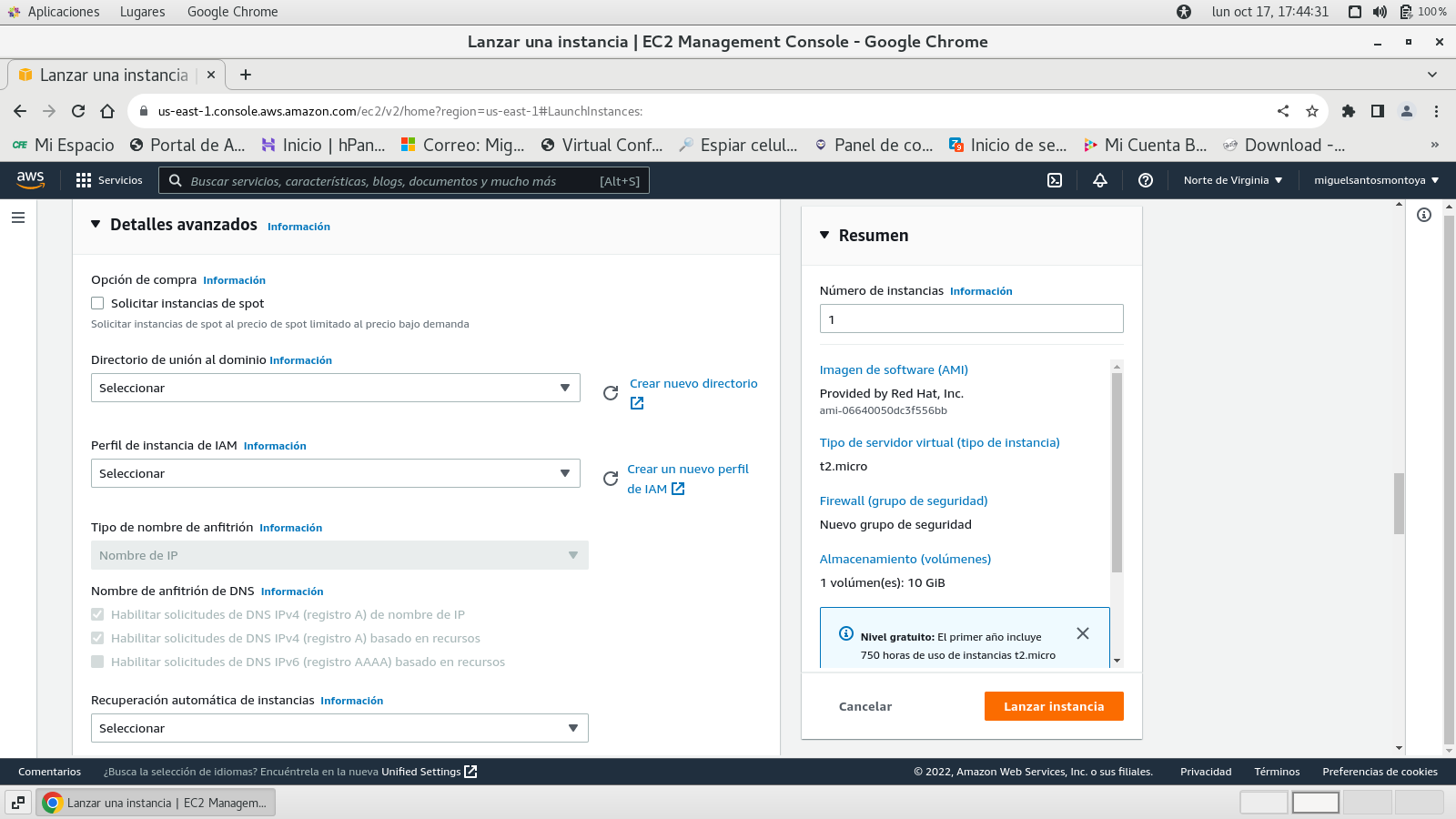
Resumen (al lado derecho de la página)
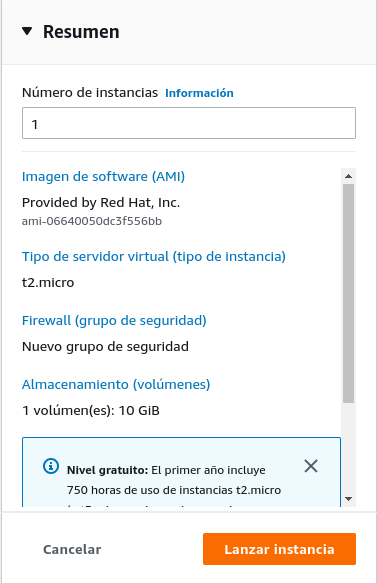
Lanzar instancia
Instancia terminada
Conectarse a la instancia
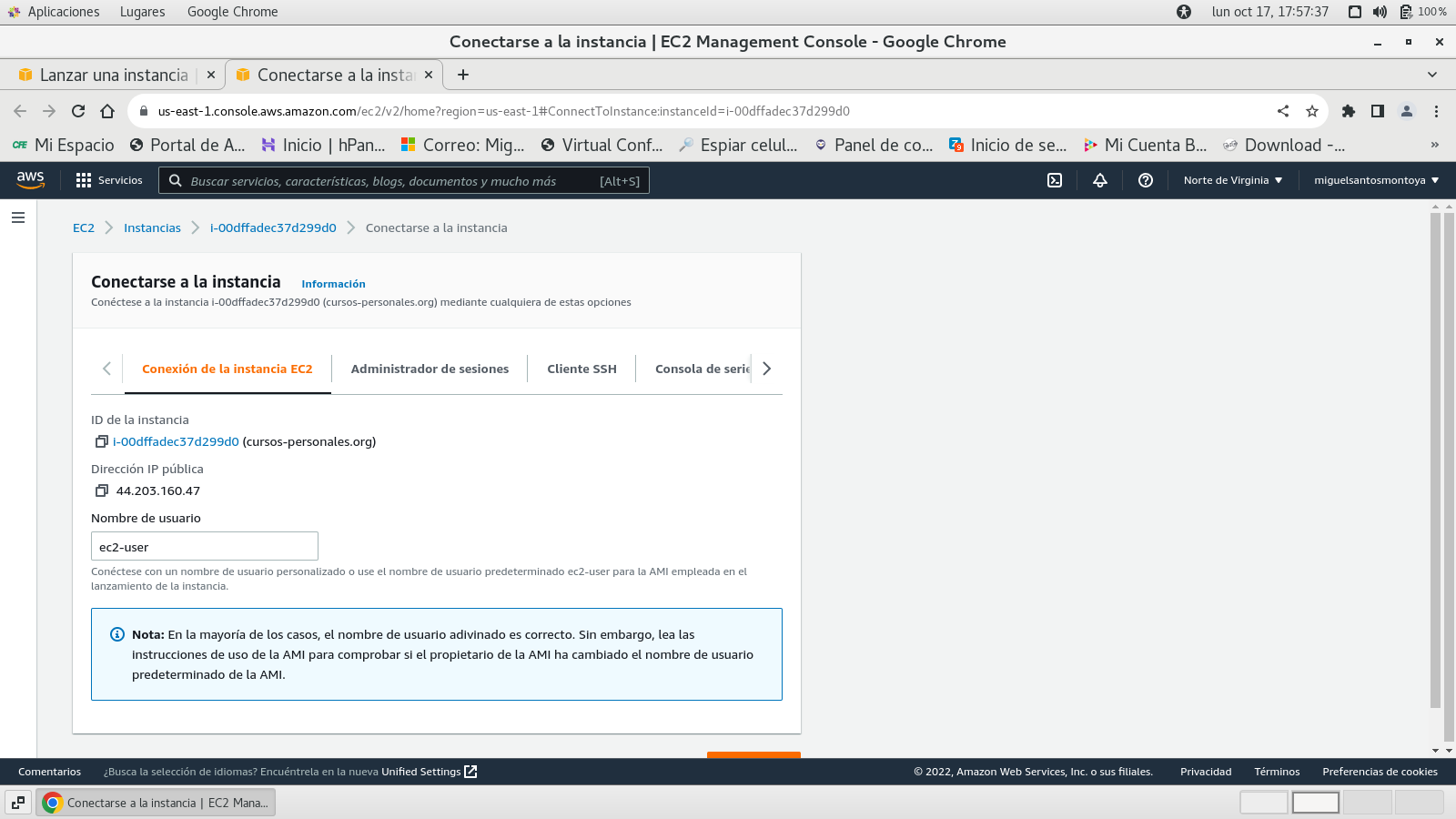
cliente ssh
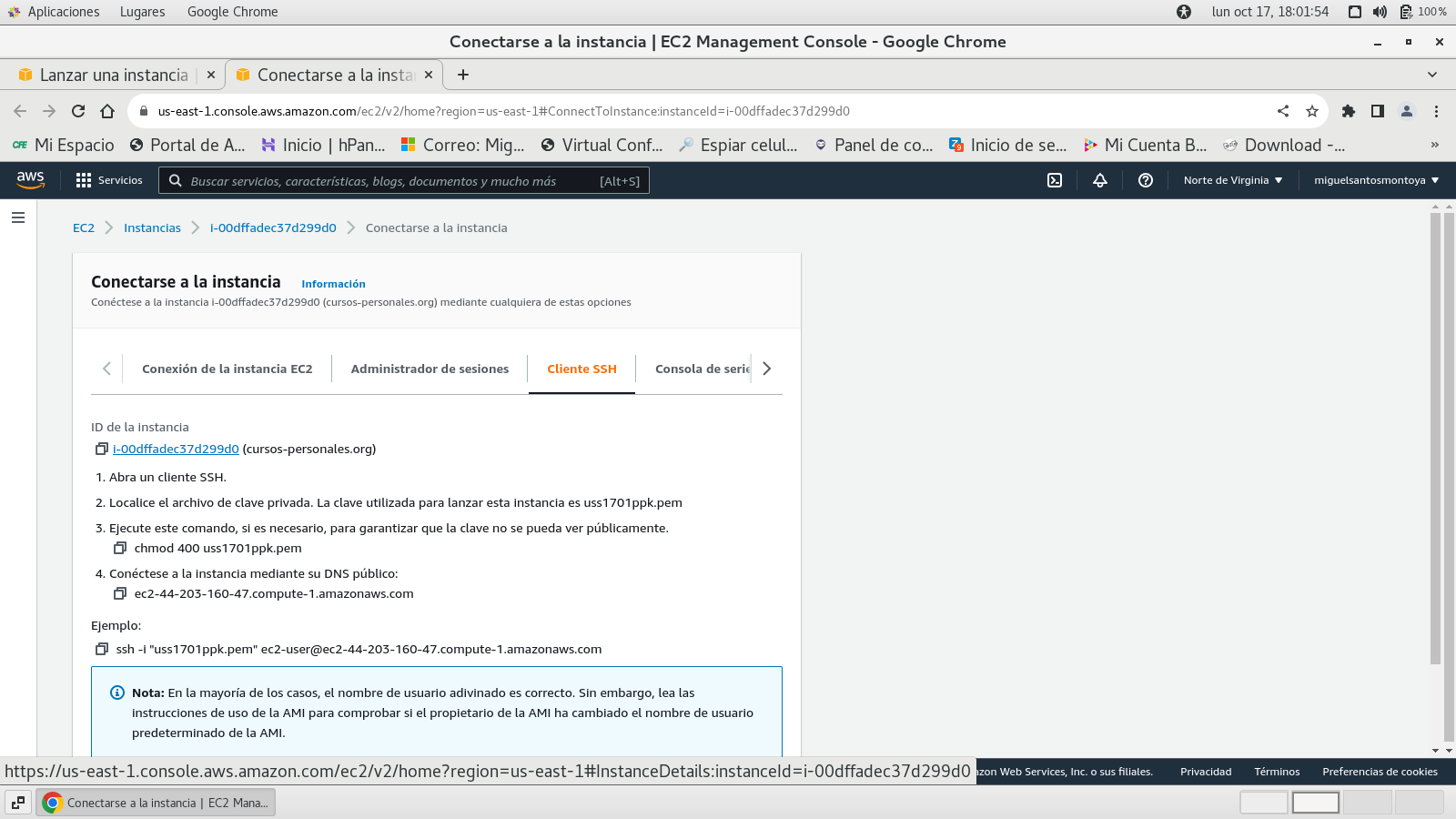

Se puede apreciar que para tengamos
algo moderadamente bien hay que contratar un servicio con un
costo arriba de los 80 US.
Google
Cloud
Descripción general de Google Cloud
Google Cloud consiste en un conjunto
de recursos físicos, como computadoras y unidades de disco
duro, y recursos virtuales, como máquinas virtuales (VM),
que se encuentran en los centros de datos de Google en todo
el mundo.
Recursos de Google Cloud
Google Cloud consiste
en un conjunto de recursos físicos, como computadoras y
unidades de disco duro, y recursos virtuales, como máquinas
virtuales (VM), que se encuentran en los centros de datos de
Google en todo el mundo. Cada centro de datos está ubicado
en una región, específicamente en Asia, Australia, Europa,
América del Norte y América del Sur. Cada región es una
colección de zonas aisladas entre sí dentro de cada región.
Estas zonas se identifican mediante nombres que combinan una
letra identificadora con el nombre de la región. Por
ejemplo, la zona a en la región de Asia Oriental se llama
asia-east1-a.
Esta distribución de los recursos
brinda varios beneficios, que incluyen redundancia en caso
de fallas y menor latencia, ya que los recursos se
encuentran más cerca de los clientes. La distribución
también presenta algunas reglas sobre cómo se pueden usar
los recursos en conjunto.
Acceder a los recursos a través de los
servicios
En la computación en la nube, lo que
conocías como productos de software y hardware pasan a ser
servicios. Con ellos puedes acceder a los recursos
subyacentes. La lista de servicios de Google Cloud
disponibles es larga y está en constante crecimiento. Cuando
desarrollas tu sitio web o aplicación en Google Cloud,
combinas y mezclas estos servicios para proporcionar la
infraestructura que necesitas y, luego, agregas tu código
para crear lo que deseas.
Iniciamos con el acceso:
clic sobre google cloud

botón Comenzar sin costo
solicita una cuenta de gmail:

ingresando el correo nos presenta la
siguiente información:

completamos lo que nos solicita
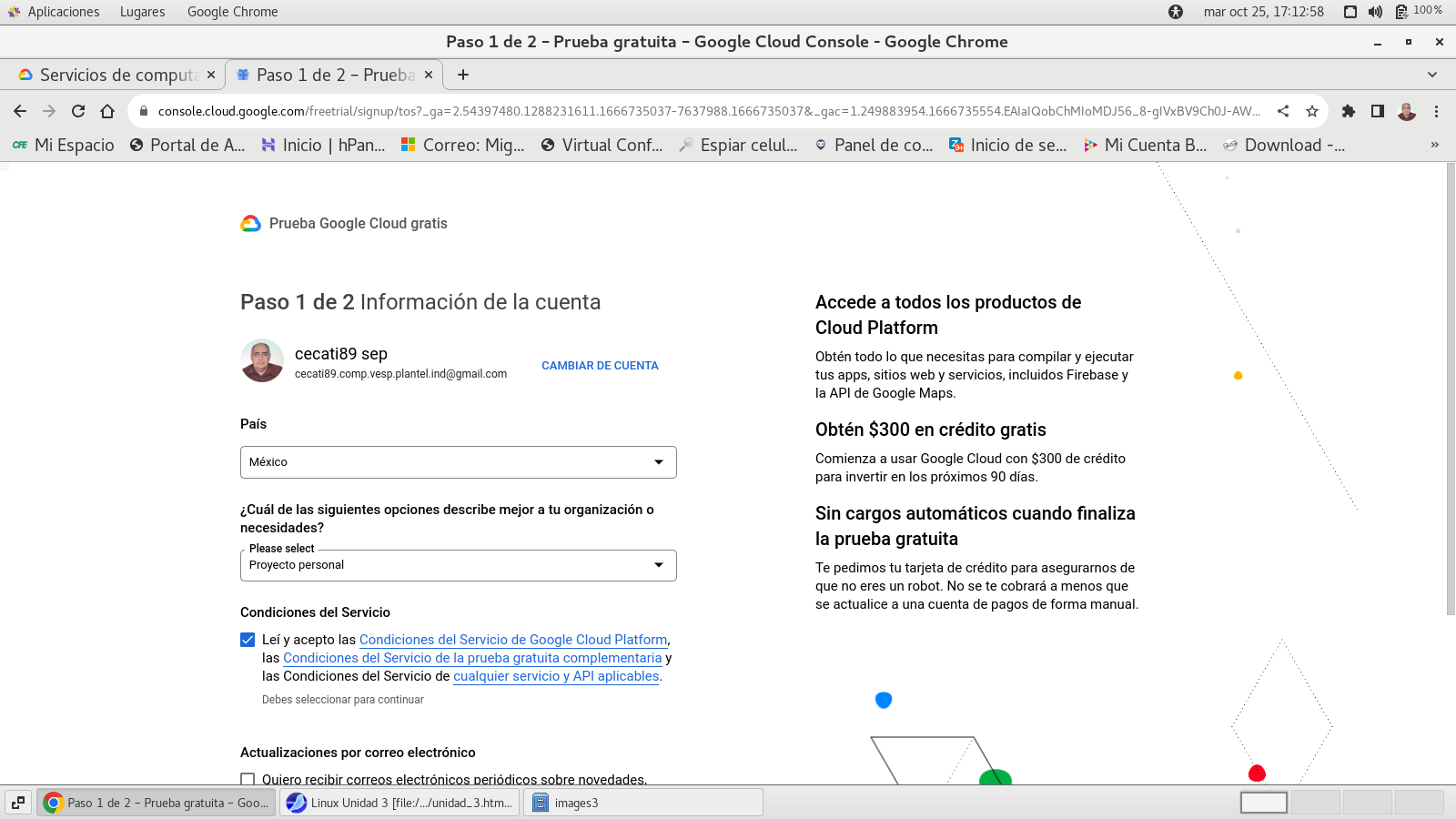
terminamos con continuar

Llenamos los datos que nos solicitan
para confirmación (paso 2) prueba gratuita

nos solicitan un numero de tarjeta de
crédito (valida)

y clic en el botón INICIAR PRUEBA
GRATUITA, y configuramos el resto de las opciones.
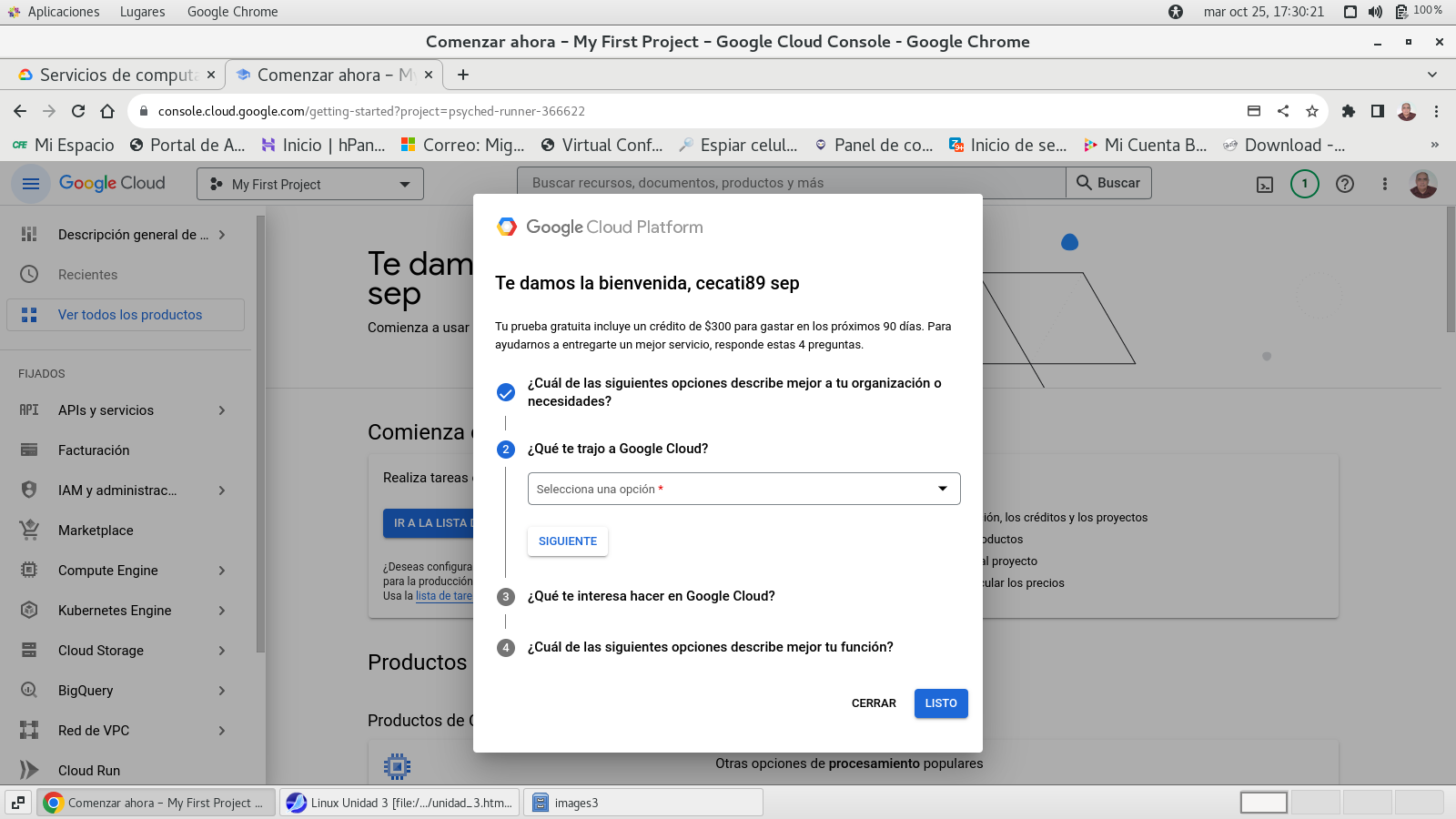
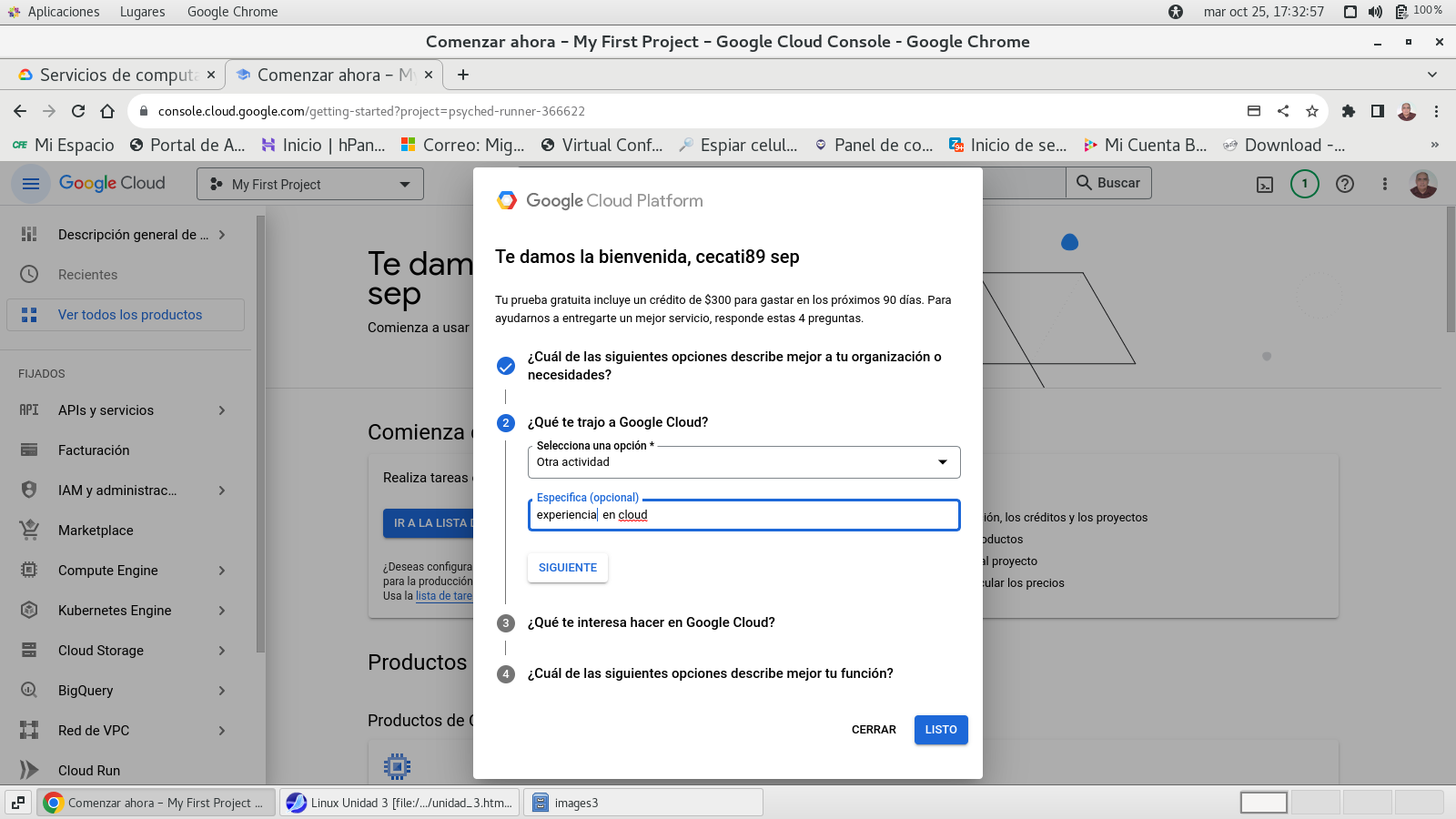
botón SIGUIENTE
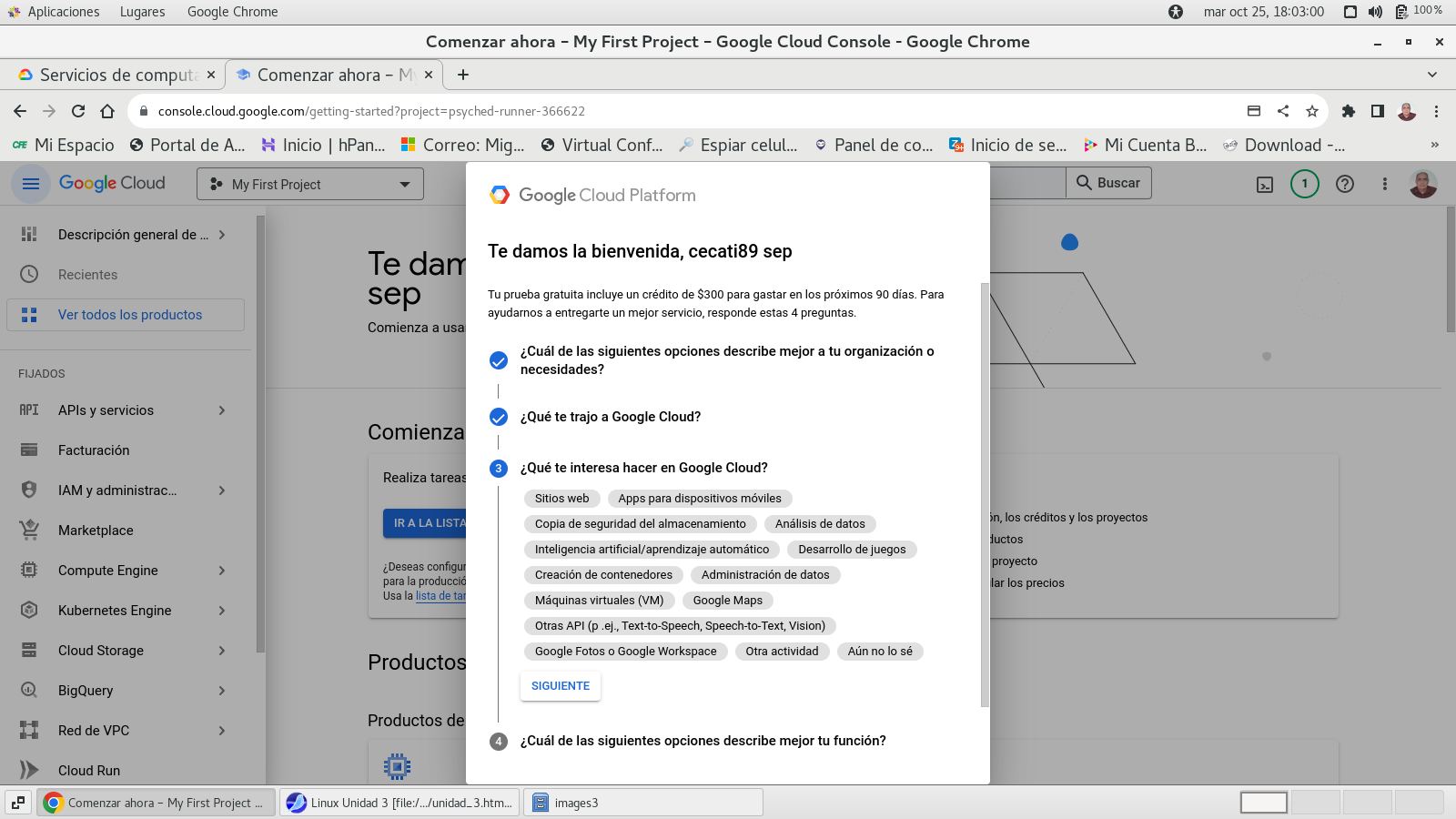
seleccionamos el uso principal del
cloud de google
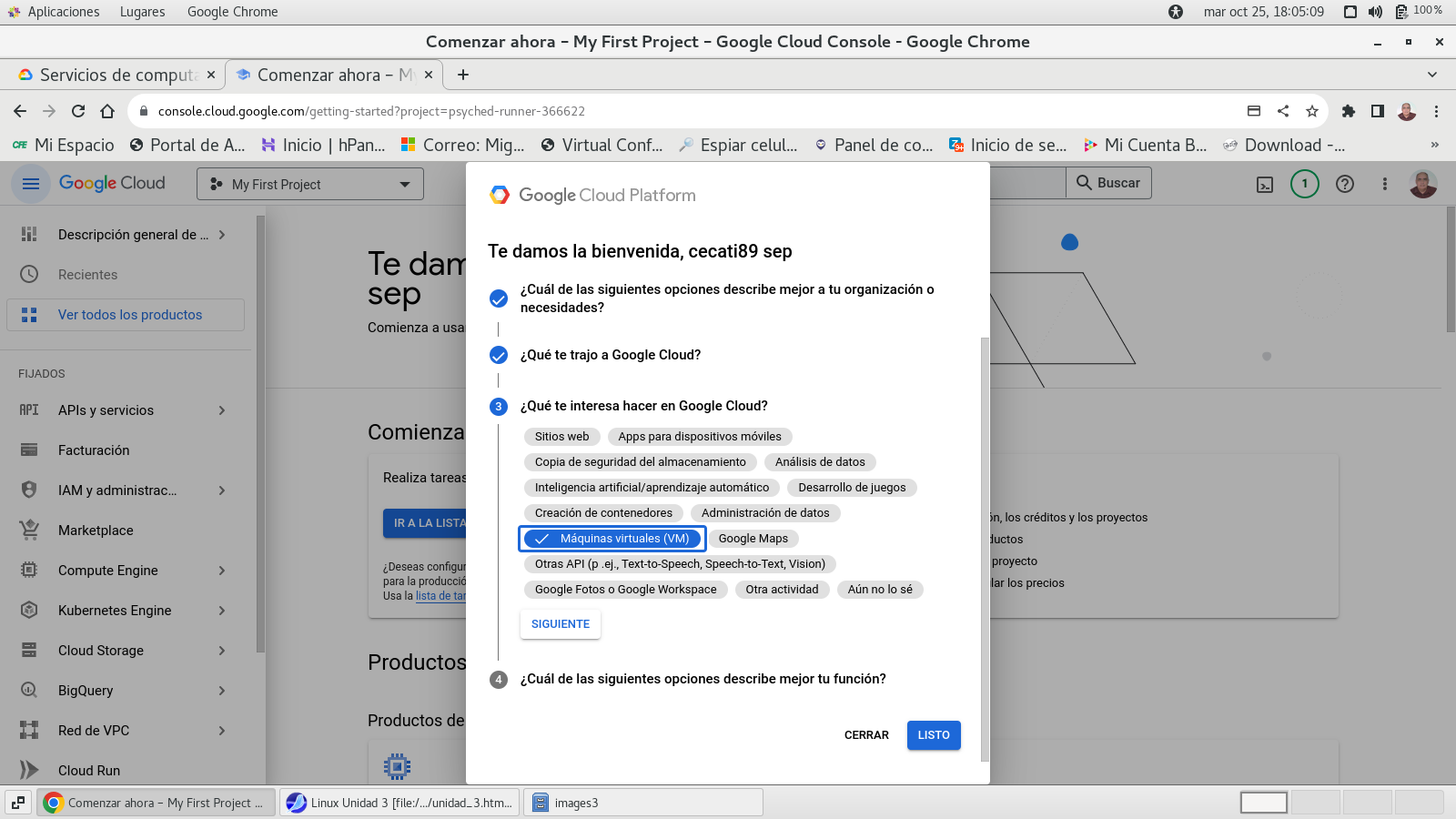
Botón SIGUIENTE
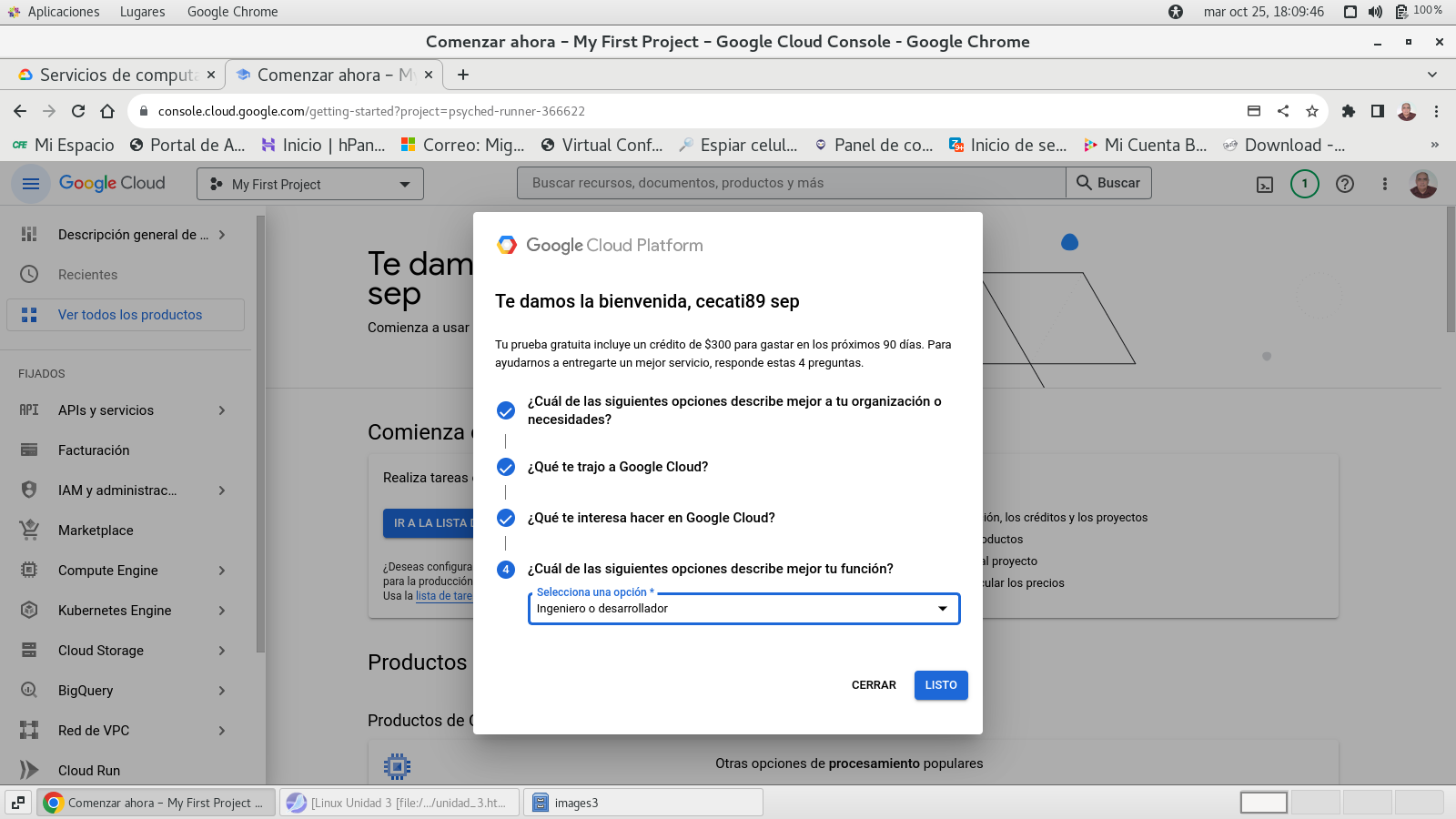
terminamos con LISTO
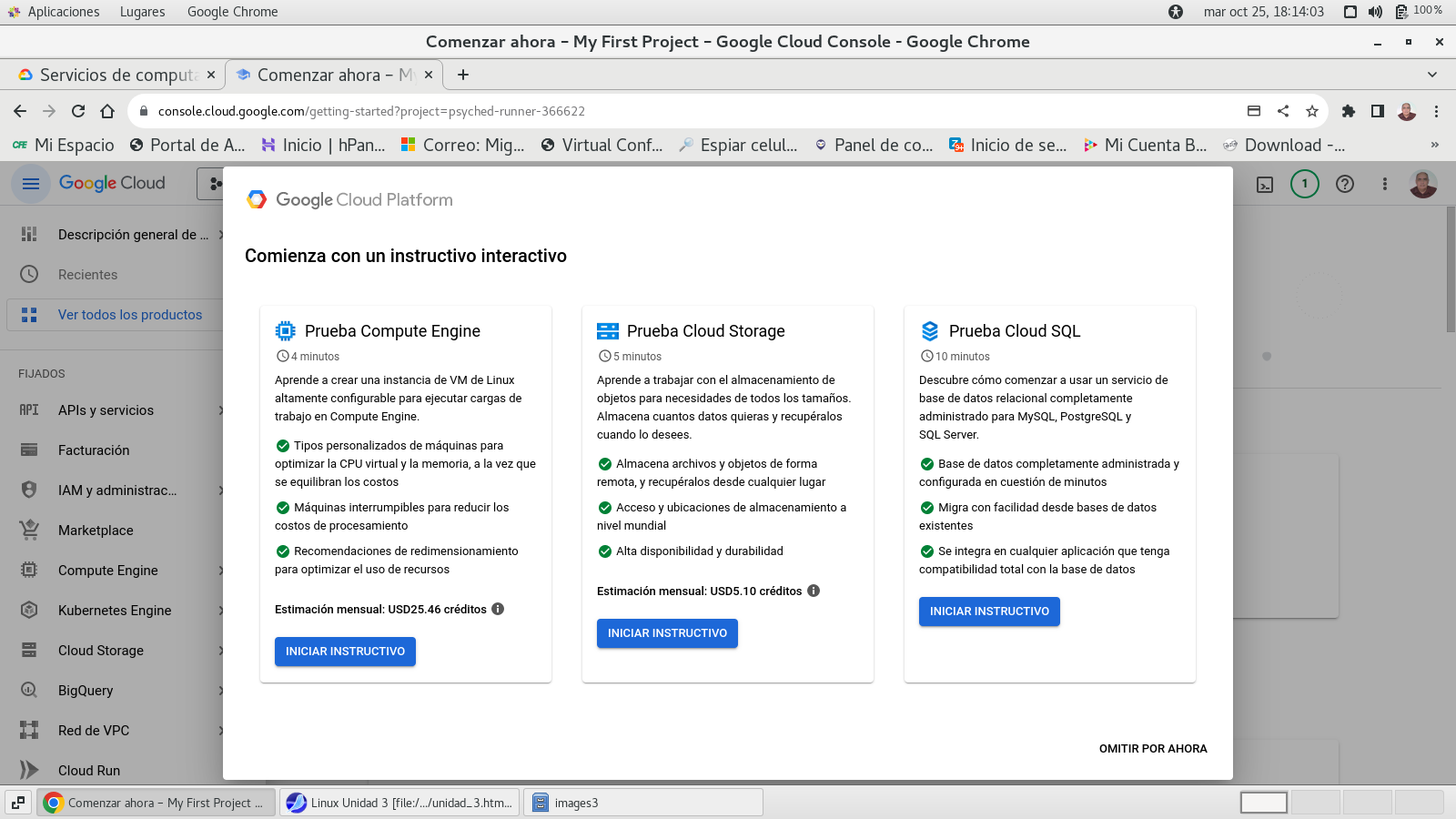
Usamos CloudShell
y aquí el shell:
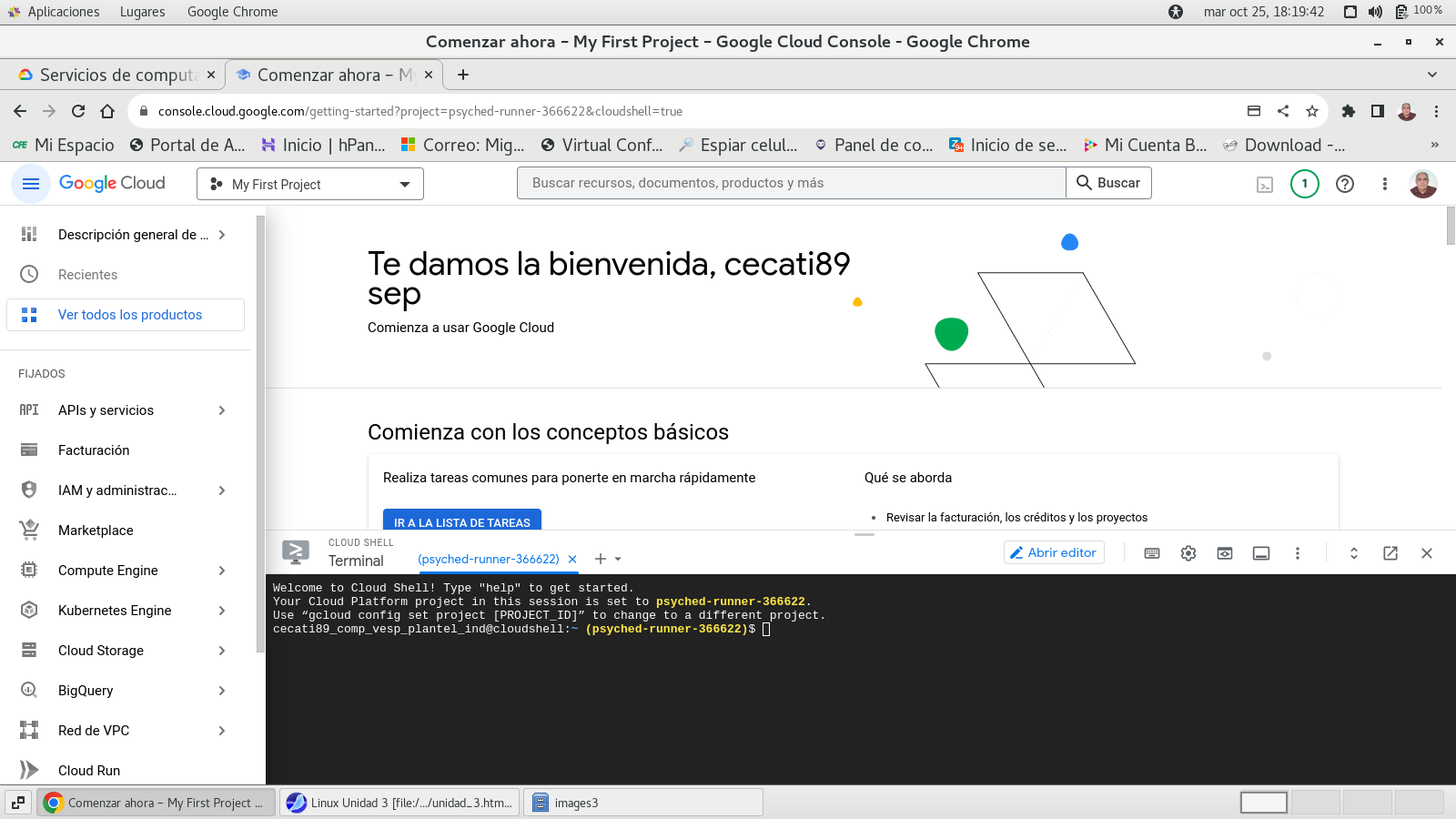
de aquí dependerá de que servicios
deseamos usar (187 actualmente)
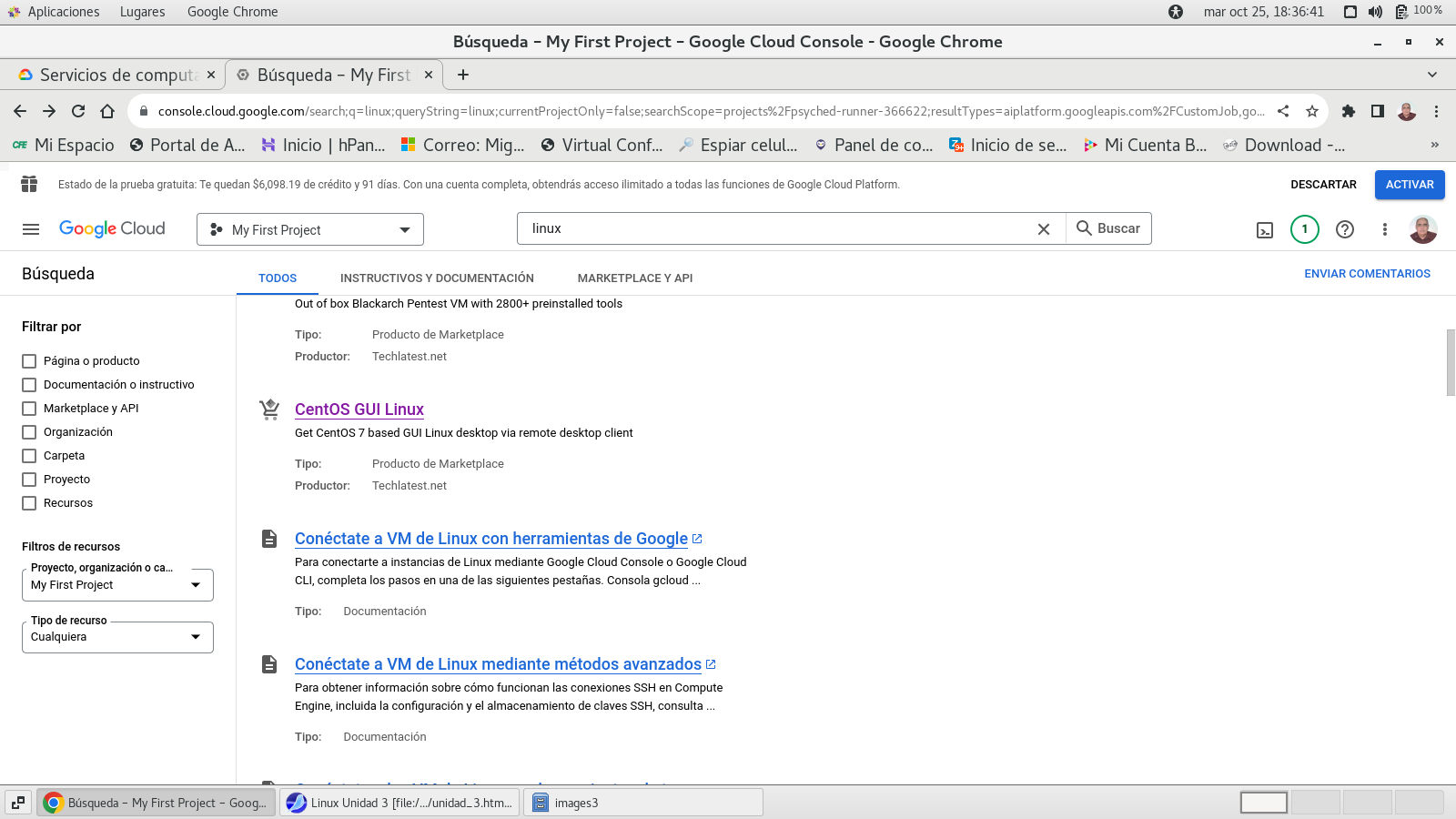
se deberá de revisar que servicios de
api a usar.
GIT
Git es un sistema de
control de versiones distribuido, diseñado por Linus
Torvalds. Está pensando en la eficiencia y la confiabilidad
del mantenimiento de versiones de aplicaciones cuando estas
tienen un gran número de archivos de código fuente.
Git fue creado
pensando en la eficiencia y la confiabilidad del
mantenimiento de versiones de aplicaciones cuando éstas
tienen un gran número de archivos de código fuente, es decir
Git nos proporciona las herramientas para desarrollar un
trabajo en equipo de manera inteligente y rápida y por
trabajo nos referimos a algún software o página que implique
código el cual necesitemos hacerlo con un grupo de personas.
Qué es un sistema de control de
versiones?
El SCV o VCS (por sus
siglas en inglés) es un sistema que registra los cambios
realizados sobre un archivo o conjunto de archivos a lo
largo del tiempo, de modo que puedas llevar el historial del
ciclo de vida de un proyecto, comparar cambios a lo largo
del tiempo, ver quién los realizó o revertir el proyecto
entero a un estado anterior.
Por qué usar Git
Git es la primera
pieza de cualquier set de herramientas para el desarrollo
moderno. Forma parte del día a día de los desarrolladores
profesionales, de los equipos de desarrollo y de los
profesionales devOps.(conjunto de los equipos de desarrollo
y operaciones)
Controlar las versiones del código
Sirve para el control
de versiones de los proyectos y por ello permite saber todos
los estados por los que han pasado cada uno de los archivos
de código de un proyecto. Permite saber cuándo se modificó
un archivo y qué cambios se realizaron, a lo largo de toda
la existencia de ese archivo.
Trabajo en equipo
Git es la herramienta fundamental para trabajo en equipo, ya
que permite que cada desarrollador trabaje con su propia copia
local del proyecto y, cuando envíe cambios al repositorio
global, se asegure que su código no machaca modificaciones
introducidas por otros desarrolladores.
Ademas gracias a Git cualquier desarrollador puede
sincronizar el código del proyecto local con los cambios
introducidos por otros desarrolladores, lo que facilita mucho
el día a día del trabajo de todos los desarrolladores y la
gestión de proyectos.
Revisar el código del proyecto en equipo
Otra de las ventajas de Git para equipos de trabajo es que
podemos revisar cualquier actualización del código del
proyecto entre varias personas. Un desarrollador envía un pull
request y otro u otros desarrolladores pueden verificar que
los cambios tienen buena pinta, antes de incorporarlos al
proyecto.
Revisar la calidad del código y pasar las pruebas
Con Git podemos automatizar diversos procesos de
comprobación de la calidad del código, como los que nos
permiten los linters o las pruebas. Estas comprobaciones se
pueden realizar con cualquier intento de enviar código al
repositorio. Si no pasa la revisión del Linter o las pruebas,
simplemente no se permitirá actualizar el código del proyecto.
Estos sistemas facilitan aportar un estándar de codificación
que tendrán que seguir todos los profesionales del proyecto.
Si se intenta enviar cambios al proyecto y el formato o las
buenas prácticas no se están siguiendo correctamente, Git no
permitirá la actualización del código. Por supuesto, si todas
las pruebas unitarias no pasan correctamente, tampoco se podrá
actualizar el proyecto.
Despliegue de aplicaciones web
Con Git puedes subir un sitio web al servidor en cuestión de
instantes, sin usar FTP. Además, cuando se actualiza el código
del proyecto puedes usar Git para subir únicamente aquellos
archivos que se han modificado, con un sencillo comando de
consola.
Aunque no usemos todo el potencial de las operaciones con Git,
solo si conseguimos sustituir FTP, estaremos ganando mucha
facilidad de organización de proyectos medianos y grandes.
instalamos GIT,
dnf install git-all -y



requerimos añadir y habilitar documentación en varios formatos
(doc, html, info) son necesarias estas dependencias.
yum install asciidoc xmlto docbook2X -y


instalamos gnu-getopt este no esta en el repositorio de CentOS
hay que descargarlo, desde la pagina RPMfind, si se tienen
problemas al encontrar la pagina al final de este tema esta el
archivo, solo hacemos clic en el para descargarlo



lo descargamos desde la pagina e instalamos


Además, si está utilizando derivados de Fedora/RHEL/RHEL, debe
hacer esto:
 git clone git://git.kernel.org/pub/scm/git/git.git
git clone git://git.kernel.org/pub/scm/git/git.git

Configuración
de Git por primera vez
Ahora que tiene Git en su sistema, querrá
hacer algunas cosas para personalizar su ambiente GIT. Debería
tener que hacer estas cosas solo una vez en cualquier
computadora; se unirán a las actualizaciones. También puede
cambiarlos en cualquier momento ejecutando a través de los
comandos de nuevo.
Git viene con una herramienta llamada git
config que le permite obtener y establecer variables de
configuración que controlan todos los aspectos de cómo se ve y
opera Git. Estas variables se pueden almacenar en tres lugares
diferentes:
1. Archivo [ruta]/etc/gitconfig: Contiene
valores aplicados a cada usuario en el sistema y todos sus
repositorios Si pasa la opción --system a git config, lee y
escribe desde este archivo específicamente. Debido a que se
trata de un archivo de configuración del sistema, necesitaría
información administrativa o privilegio de superusuario para
realizar cambios en él.
2. Archivo ~/.gitconfig o
~/.config/git/config: valores específicos personalmente para
usted, el usuario. Puedes hacer que Git lea y escriba en este
archivo específicamente al pasar la opción --global, y esto
afecta todos los repositorios con los que trabaja en su sistema.
3. archivo de configuración en el directorio Git (es decir,
.git/config) de cualquier repositorio que esté actualmente
usando: Específico para ese único repositorio. Puede obligar a
Git a leer y escribir en este archivo con la opción --local,
pero de hecho es la predeterminada. Como era de esperar,
necesita estar ubicado en algún lugar de un repositorio de Git
para que esta opción funcione correctamente.
Cada nivel anula los valores del nivel anterior, por lo que
los valores en .git/config superan a los de
[ruta]/etc/gitconfig.
Tu identidad
Lo primero que debe hacer cuando instala Git es configurar su
nombre de usuario y dirección de correo electrónico. Este es
importante porque cada confirmación de Git usa esta información,
y está integrada inmutablemente en el se compromete a empezar a
crear:


Nuevamente, debe hacer esto solo una vez si
pasa la opción --global, porque entonces Git siempre use esa
información para cualquier cosa que haga en ese sistema. Si
desea anular esto con un nombre o dirección de correo
electrónico diferente para proyectos específicos, puede ejecutar
el comando sin el --opción global cuando estás en ese proyecto.
Muchas de las herramientas GUI le ayudarán a
hacer esto cuando las ejecute por primera vez.
Tu editor
Ahora que su identidad está configurada, puede
configurar el editor de texto predeterminado que se usará cuando
Git necesita que escribas un mensaje. Si no está configurado,
Git usa el editor predeterminado de su sistema. Pudeses usar
cualquier editor vi, nano, etc.
git config --global core.editor vi

Su nombre de sucursal predeterminado
Por defecto, Git creará una rama llamada
master cuando crees un nuevo repositorio con git init. Desde la
versión 2.28 de Git en adelante, puede establecer un nombre
diferente para la rama inicial.
Para configurar main como el nombre de rama
predeterminado, haz lo siguiente:
git config --global init.defaultBranch principal

Comprobación de su configuración
Si desea verificar sus ajustes de configuración, puede usar el
comando git config --list para enumerar todas las
configuraciones que Git puede encontrar en ese punto:
git config --list

para verificar la configuracion de git con el editor
seleccionado :
git config --global -e

Salimos del editor con Esc :q
Usaremos core.autocrlf
para que sirve ?
Git se puede usar en LINUX, MacOS, y
windows, y se puede intercambiar entre ellos, pero existe
un problema en Windows y los repositorios, Windows agregara 2
caracteres especiales al final de cada linea, CR y LF (CR -
Carriage Return , retorno de carro, o el ENTER, y LF Line Feed
avance de linea), en el caso de LINUX o MacOS, en cada linea se
termina con un LF, el que desarrolla en windows deberá eliminar
el CR cuando sube al repositorio, pero si desea descargar del
repositorio deberá agregarlo cuando pase del repositorio a
Windows, para esto el valor de configuración deberá ser "true",
en el caso de LINUX o MacOS, GIT no deberá hacer alguna acción,
pero puede ser que alguien ya sea el usuario agregue CR, o el
editor lo haga, deberemos de asegurar que no pase CR al
repositorio así que debemos establecer "input" en nuestro caso
en LINUX ES INPUT:
git config --global core.autocrln input

y comprobando la configuración:
git config --global -e

Obteniendo ayuda
Si alguna vez necesita ayuda mientras usa Git, hay tres formas
equivalentes de obtener el completo ayuda de la página de manual
(manpage) para cualquiera de los comandos de Git:
$ git help <verb>
$ git <verb> --help
$ man git-<verb>
Por ejemplo, puede obtener la ayuda
de la página de manual para el comando git config ejecutando
este: git help config

Además, si no necesita la ayuda completa de la
página de manual, pero solo necesita una actualización rápida en
el opciones disponibles para un comando de Git, puede solicitar
la salida de "ayuda" más concisa con -h opción, como en:
git add -h

Conceptos
básicos de Git
cubriremos todos los aspectos básicos de
comando que necesita para hacer la gran mayoría de las cosas que
eventualmente dedicará su tiempo a hacer con Git. Al final,
debería poder configurar e inicializar un repositorio, comenzar
y dejar de rastrear archivos, y preparar , y confirmar cambios.
También le mostraremos cómo configurar Git
para ignorar ciertos archivos y patrones de archivo, cómo
deshacer errores rápida y fácilmente, cómo navegar por historial
de su proyecto y ver los cambios entre las confirmaciones, y
cómo empujar y extraer desde el control remoto repositorios.
Inicializar un repositorio en un directorio
Si tiene un directorio de proyectos que
actualmente no está bajo control de versiones y desea comenzar
controlándolo con Git, primero debe ir al directorio de ese
proyecto. Si nunca has hecho esto, es se ve un poco diferente
según el sistema que esté ejecutando:
para LINUX
$ mkdir /home/msantos/Documentos/proyecto_git
$ cd /home/msantos/Documentos/proyecto_git

y tecleamos:
$ git init
Esto crea un nuevo subdirectorio llamado .git que contiene
todos los archivos necesarios del repositorio: un Esqueleto del
repositorio Git. En este punto, todavía no se realiza un
seguimiento de nada en su proyecto.
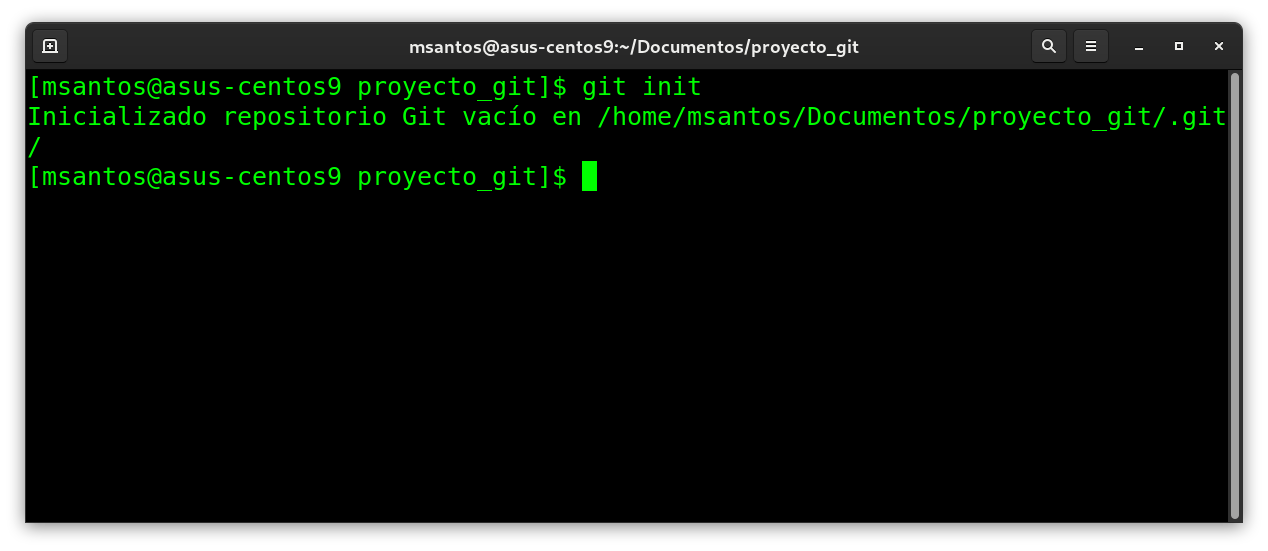
$ git commit -m 'version proyecto inicial'
Repasaremos lo que hace este comando.
En este punto, tienes un repositorio de Git, con una
confirmación (commit) inicial.

inicialmente solicitamos el estado de git:
git status
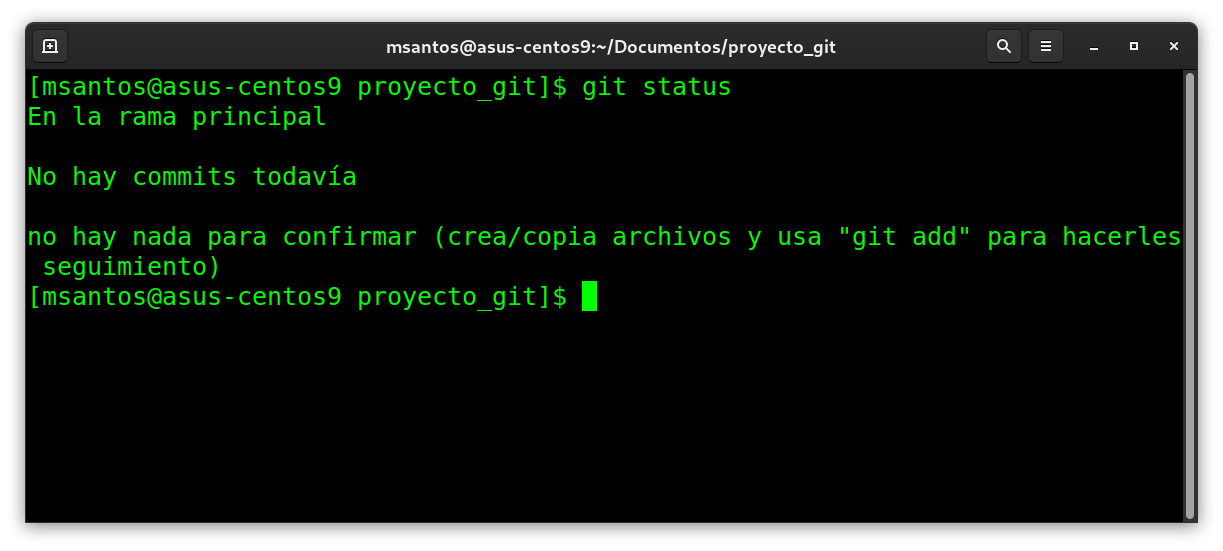
estamos observando que estamos en el arbol master (On branch
master), en este caso lo llamamos principal anteriormente.
antes de continuar crearemos un directorio llamado Linux,
mkdir /home/msantos/Documentos/Linux, en el cual primeramente
crearemos una serie de archivos vacios, como a continuación se
describen:
cd /home/msantos/Documentos/Linux
touch unidad_1_linux9.html unidad_2_anexo1.html
unidad_2_anexo2.html unidad_2_linux9.html unidad_3_linux9.html
unidad_linux_loc_os.html
con esto estamos realizando una suposición que tenemos
archivos de tipo .html (archivos para pagina web), esto es para
realizar el ejercicio, puden ser cualquier tipo .txt , .c , c++,
etc. en resumen cualquier desarrolo que se este realizando aa
regresamos al directorio donde estamos creando el repositorio
de git
cd /home/msantos/Documentos/proyecto_git
en el directorio de proyecto_git, copiamos el grupo de
archivos (directorio) que necesitamos "controlar", en este caso
como ejemplo copiamos al directorio el "directorio" Linux:

al solicitar el status de git, mostrara que tiene un
directorio llamado Linux. Indicando que no se ha realizado el
"commit" para procesar el directorio:
git status

Puede ver que su nuevo Directorio Linux no
tiene seguimiento, porque está bajo el encabezado Untracked
files: "Archivos sin seguimiento" en su salida de estado. Sin
seguimiento básicamente significa que Git ve un directorio que
no tenías anteriormente (confirmación) y que aún no se ha
preparado; Git no comenzará a incluirlo en tu confirmación
instantáneas hasta que le digas explícitamente que lo haga. Hace
esto para que no comience a incluir accidentalmente.
El proceso de trabajo de GIT
COMPUTADORA LINUX / Mac / windows
|
|
Stage
|
Commit
|
Server
|
Usuario
|
Pasamos todos los
archivos que nos interesen guardar en el repositorio
que serán actualizados estos
archivos serán trasladados a lo que se llama Stage
--------->
|
Punto intermedio que
indica cuales son los archivos que van al
repositorio, y solo pasaran aquellos que seleccionemos
ya que se han establecido los
archivos a guardar en el repositorio usamos el
paso hacia commit --------->
|
es el lugar donde
esta definido el repositorio es
opcional, pero se recomienda enviat el repositorio
hacia un servidor en la nuble donde estaran
todos los archivos que nos interesan
|
GIT
HUB
|
Archivo
1
|
Archivo 2
|
Archivo n ....
|
Acciones
|
git add
|
|
git commit (comprometer archivos)
|
|
ahora git agregara todos los archivos del
directorio a un "stage", en este ejemplo estoy seleccionando un
directorio, usando *.* que estos metacaracteres indican que tome
TODO, esto solo si estamos seguros que es lo que queremos, puede
ser que solo los de *.hmtl sean los que estamos haciendo
seguimiento, u otro tipo de archivo.
git add *
(git add *) indica que todos los direcrorios / archivos lo
estaremos preparando, para enviarlos a stage, y solicitamos el
estatus de git
git status

esto pude tardar tiempo, cuando sean muchos archivos, que
fueron agregados los archivos del directorio de Linux, en la
imagen de git status esta mostrando que estamos en la rama
master (principal):
On branch master
En la rama principal
y hay cambios listos para realizar commit (comprometidos)
Changes to be committed:
Cambios a ser comprometidos:
vamos a realizar un proceso donde pasamos archivos modificados
regresamos al directorio cd /home/msantos/Documentos/Linux
creamos otro archivo y lo llamamos manual_datos.txt
touch manual_datos.txt

regresamos al contenedor:
cd /home/msantos/Documentos/proyectos_git
copiamos del directorio original
/home/msantos/Documentos/Linux, al contenedor:

Solicitamos status, de nuevo lo analizamos:
git status

Notamos que ha detectado un cambio en los archivos nuevos es
de manual_datos.txt
para que realice el cambio debemos de nuevo agregar con git
add

y de nuevo revisamos el status, y lo ha incluido en el stage
git status

lo que estamos haciendo en realidad, es estar pasando los
archivos que se han modificado al stage
Commit
ya estan listos para realizar el commit (comprometer los
archivos)
debemos de poner un nombre de lo que estamos realizando entre
comillas dobles para saber en que revision, o comentario de lo
que estamos creando, en este ejemplo revisión de diseños
git commit -m "revision de diseños"

con esto comprometemos los archivos que estamos añadiendo al
repositorio, solicitamos el status: git status

y no hay procesos pendientes de commit
regresamos al directorio Linux (origen de archivos)
cd /home/msantos/Documentos/Linux
y creamos otro directorio dentro de Linux, lo llamamos CentOS9

Ingresamos a este nuevo subdirectorio, creamos otro archivo
ahí, lo llamaremos centos_documentacion

tenemos otro método, que es el siguiente, volvemos al
directorio del contenedor, y copiamos el directorio original de
donde estoy trabajando, y lo que he modificando:
cp -r /home/msantos/Ddocumentos/Linux/* .

ahora he realizado la copia con algo diferente, la ruta
(path) es el mismo de origen pero agregue -r (Recursivo,
considera también los directorios y subdirectorios, y como estoy
en el directorio Linux del repositorio colocamos ( . ) que
significa el directorio actual.
git status

y al usar git status, también nos indica que hay cambios, un
directorio CentOS9
Estando en el contenedor proyecto_git, lo agregamos es
importante que realicemos esto cada ocación que se modifique
algo:
git add CentOS9
debemos ser cuidadosos en el caso de los
directorios para añadir a git ya que se debe de establecer la
ruta completa, de lo contrario marcara un error, que no existe
directorio / archivo, cuando se realiza sin problema seria asi:

ahora ejecutamos commit de esta otra forma:
git commit
lo que sucedera es, QUE SE ABRIRA EL EDITOR DE TEXTOS QUE
SELECCIONAMOS COMO PREFERIDO EN LA CONFIGURACIÓN INICIAL,
mostrando que se ha añadido el directorio y el archivo que se
han copiado previamente (esto sucede cuando agregamos rutas al
contenedor) deberemos de indicarle que "objeto(s)" se an
agregado con un titulo del este cambio,

y agregamos al inicio una descripción de este commit, esta en
la primer linea y se observa el archivo a agregar,
CentOS9-archivos y guardamos el archivo Esc:wq

al terminar tenemos información de la operación realizada:

nos proporciona mas información sobre los que realizo,
solicitamos su status:
git status

Eliminaremos un archivo del directorio
Linux, en el contenedor, nos cambiamos al directorio
cd Linux/
ls -l|more
revisamos, quiero eliminar el archivo manual_datos.txt, y escribimos rm manual_datos.txt, y ENTER, y con git
status, revisamos que esta preparado para ser eliminado del
directorio, y GIT lo detecta.

quedamos en el directorio proyecto_git y git status
de nuevo

esta preparado para ser eliminado del árbol del repositorio,
realizamos el commit : git commit -m "Eliminando
manual_datos.txt", y se puede observar que hay un error no se ha
registrado la eliminacion:

Ahora realizamos en git, para asegurar que se ha
eliminado correctamente, ya que se borro fiscalmente y lo
detecto pero del sistema de git aun esta presente, por ello hay
que eliminarlos del sistema de registro de git:
git rm Linux/manual_datos.txt

el resultado de esto, y aplicando status:

Ahora ya registro la eliminación del archivo, la siguiente
imagen se observa toda la secuencia, usamos status y commit, y
realiza la eliminacion:

Revisemos si efectivamente sucedio la eliminación, revisemos,
(recordar que estamos en el directorio Linux del
contenedor ls -l, y efectivamete el archivo no esta:

Ahora borremos a unidad_linux_loc_os.htm, con
git, pero podemos recuperaros desde stage, las razónes pueden
ser muchas: porque no era el archivo a borrar, o solo me
equivoque de archivo, en este punto podemos restaurar antes de
realizar commit:
primero borremos del árbol master el
unidad_linux_loc_os.htm
git rm unidad_linux_loc_os.htm
git status

Restaurar
archivos
aqui nos da una advertencia si lo queremos restaurar (antes de
comprometerlo "commit")
usamos:
git checkout HEAD unidad_linux_loc_os.htm
y de nuevo
git status
y ya no esta marcado para ser borrado, y es
restituido recuperado de stage

Ahora nos damos cuenta que el archivo
manual_datos.txt no era lo que queríamos borrar, pero ya se
realizao el commit, podemos recuperlo ?
si es posible !, sigamos estas instrucciones:
log
(bitacora)
git log -- manual_datos.txt
nos presenta la tabla hash, la tabla hash
asocia llaves o claves con valores. La operación principal que
soporta de manera eficiente es la búsqueda: permite el acceso a
los elementos almacenados a partir de una clave generada (usando
el nombre o número de cuenta, por ejemplo). Funciona
transformando la clave un número que identifica la posición
donde la tabla hash localiza el valor deseado)
observemos que esta el titulo "Eliminando
manual_datos.txt" y debajo de el la palabra commit con un
numero (este es el hash de la operacion) afee3327ea0ef876f217671bebcdd0c0b6636888,
este lo usaremos para recupera el archivo comprometido.

y finalmente la forma de recuperación usando hash
git checkout afee3327ea0ef876f217671bebcdd0c0b6636888

al finalizar podemos revisar si se ha realizado la
recuperación, usamos git status:

Revisemos ahora que sucede cuando cambiamos de nombre a un
archivo en el árbol master de git.
con mv cambiamos de nombre aun archivo dentro del directorio
Linux (estamos dentro de este directorio) , que se llama
unidad_1_linux9.html y la cambiaremos a unidad_1_linux9.txt
mv unidad_1_linux9.html unidad_1_linux9.txt
solicitamos git status
entre otras cosas nos esta avisando que el archivo anterior de
unidad_1_linux9.html no ha sido comprometido.
y que Linux/git_notas.txt ha sido eliminado, y
unidad_1_linux9.txt se añadio, esto es porque mv lo que realiza
es copiar el archivo inicial y pegarlo con otro nombre, y
eliminar el archivo inicial, y esto no solo sucede en Linux,
tambien en MacOS y windows, de ahi que se ven 2 operaciones
pendientes para comprometerlos.

usemos
git add *.*
(importante conocer que desde el contenedor de git también es
posible borrar, renombrar archivos)
git rm nombre_archivo
de nuevo
git status
vemos los cambios realizados y listos para comprometerlos

realizamos commit con el nombre de Archivo borrado:
git commit unidad_1_linux9.html

cuando guardamos el archivo editado por vi:

para comprometer todos aquellos que están pendientes, subimos
un nivel (cd ..) estamos en Linux/ pasamos a proyecto_git, y
agregamos lo s que faltan con: git add *.*, y comprometemos a
los faltantes con git commit *.*

y al guardar el archivo del editor de git:

realicemos una modificación en el archivo original
unidad_2_linux9.html, porque hemos realizado cambios, como
por ejemplo correcciones, mejoras, etc.
podemos realizarlo desde el directorio original:
cd /home/msantos/Documentos/Linux
vi unidad_2_linux9.html (podemos agregar cualquier texto, con
la intensión que sea diferente)
nos regresamos al contenedor de git:
cd /home/msantos /Documentos/proyecto_git
y copiamos el archivo que se modifico por mejoras y/o cambios:

ya que realizamos la copia de este archivo, nos cambiamos al
directorio Linux/ (del contenedor) revisemos el status de git,
pero ahora así:
git status -s
Mostrara lo siguiente:

M unidad_2_linux9.html
La letra M indica que este archivo fue modificado
diff
git diff
diff muestra los cambios en el archivo, observando en la parte
inferior con signos de + a lado izquierdo son los cambios que se
han hecho en el archivo que se ha copiado de nueva cuenta.
donde podemos desplazarnos para ver los
cambios hechos desde la ultima ocación que se edito, revisión de
cambios se ve como en la imagen siguiente, si son muchas las
modificaciones se mostrara una lista y para terminar esto con la
letra q, salimos.

podemos revisar el historial de lo que hemos realizado con
git log
que veríamos todo el historial de lo que hemos realizado en
gi, tambien si son muchos los datos terminas con la letra
q

pero podemos ver una lista mas reducida con:
git log --oneline

Terminamos añadiendo el archivo modificado, y realizamos el
commit y repetimos git log --oneline

recordemos que estamos en el directorio de Linux/ en su
contenedor proyecto_git, no movemos un nivel arriba y
verificamos en proyecto_git, que tengamos todo actualizado y
comprometido:
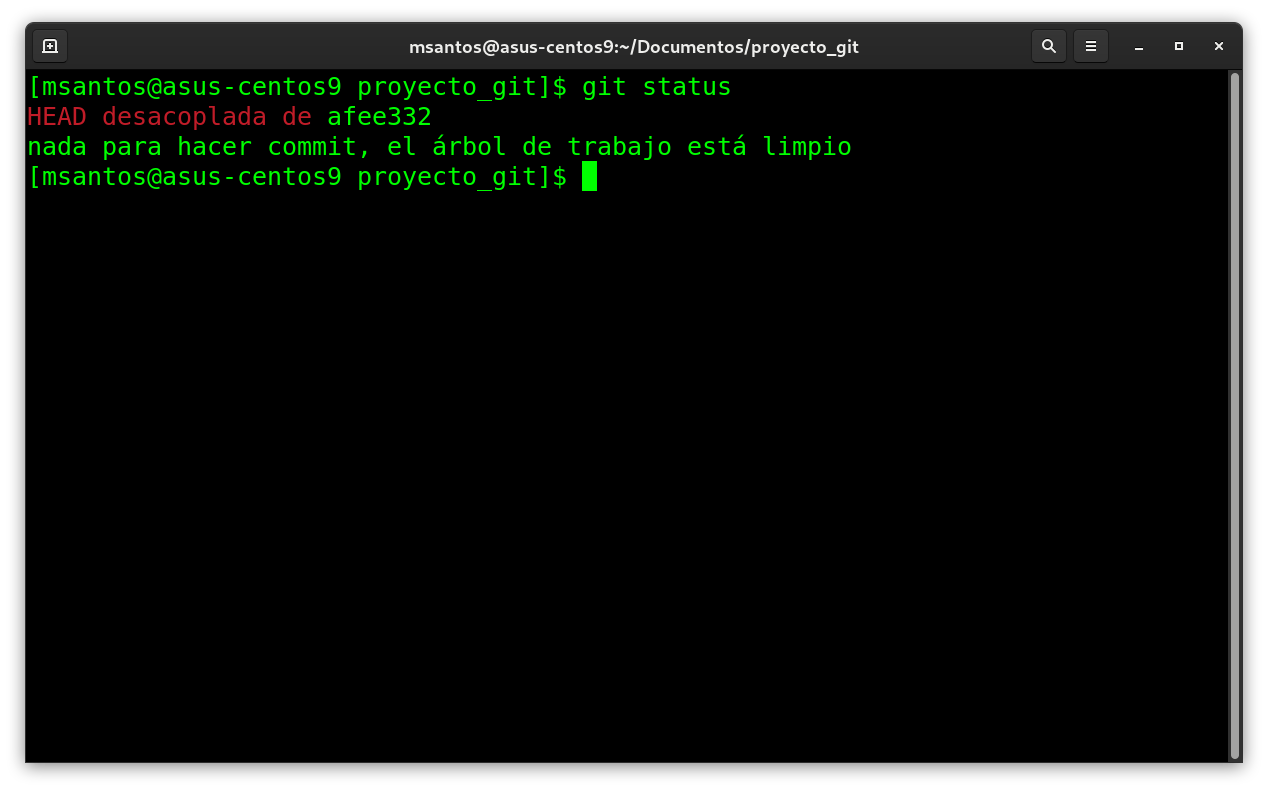
aqui vemos un mensaje que pudiera presentarse en alguna
ocación o provocado por un error en la operacion no pasa nada
con los archivos del contenedor :
HEAD desacoplada de afee332
El HEAD es un pointer o apuntador, así si como en C, este
apunta a una dirección ya sea en memoria o en este caso a un
indice de una base de datos.
tu HEAD esta apuntando a un commit especifico, puedes revisarlo,
testearlo, modificarlo, agregar, quitar, crear otra rama a
partir de esa, etc.
Para volver a “la normalidad” solo apunta de nuevo al ultimo
commit de la rama que quieres:
git checkout nombre_de_la_rama
para nuestro caso:
git checkout principal
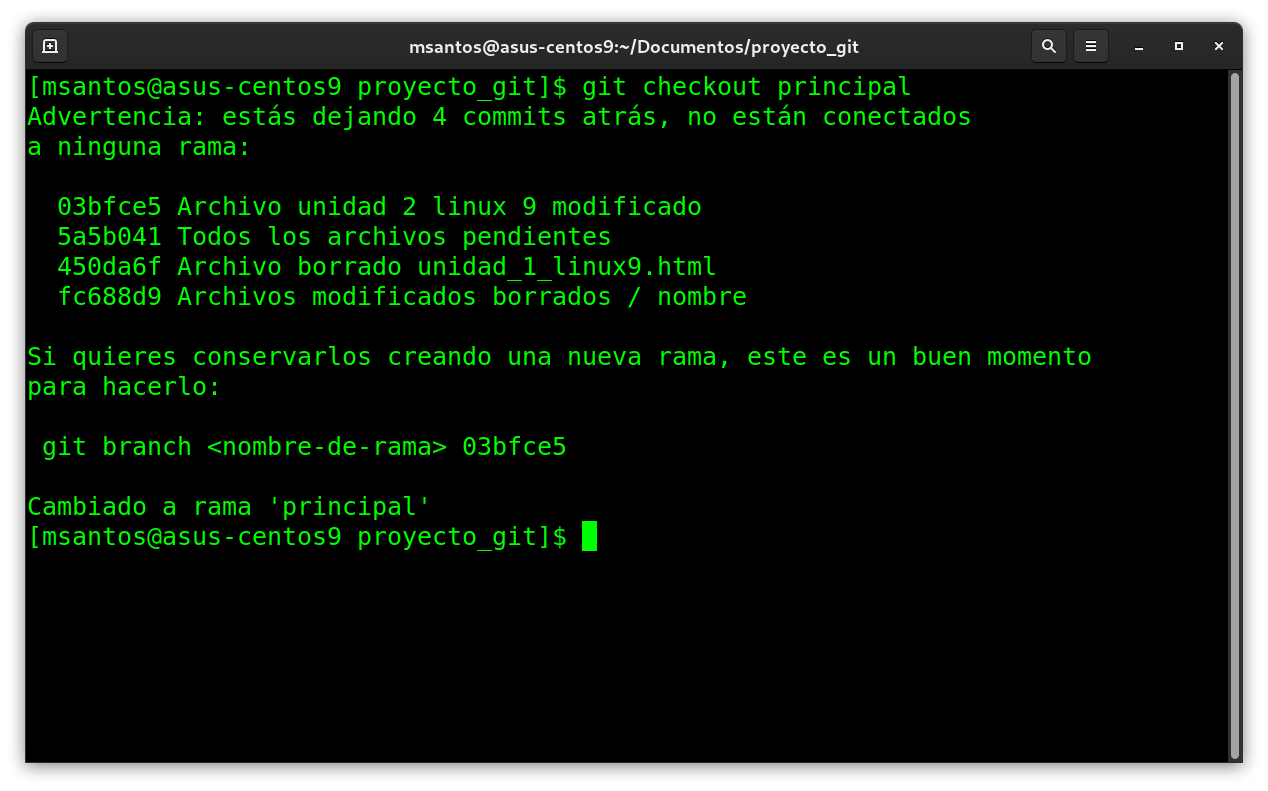
Practica :
asegurase que estas en el directorio Linux/ del contenedor, y
vuelva a copiar el archivo unidad_2_linux9.html, haga:
git status
git add unidad_2_linux9.html
git commit -m "Archivo de la unidad 2 actualizado"
y comentas el resultado
hasta aquí se ha trabajado en forma lineal, es decir he estado
realizando cambios sobre un mismo archivo o aplicación, pero es
posible que otro colaborador este haciendo modificaciones al
mismo archivo bajo su cuenta o por solicitud del organizador
inicial, así que se vera algo como esto:
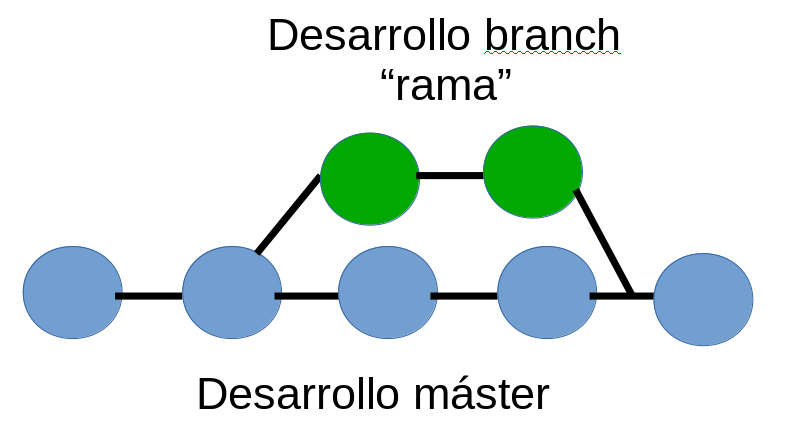
en azul lo que se esta desarrollando hasta
este momento, en verde alguien mas esta colaborando haciendo
cambios al desarrollo inicial.
se pueden separar en una rama, y luego fusionarlos (merge).
Branch
Primero debemos de revisar el status y comprobar en que rama
estoy
git status
git branch
comprobando que estoy en la rama master (la rama
principal)
* master (en nuestro caso se llama principal, se ve en la
imagen inferior con el asterisco)

para crear una rama paralela al de master hay que hacer lo
siguiente:
git checkout -b edicion_paralelo
lo que ha hecho es crear la nueva rama llamada
edicion_paralelo

si solicitamos git brench, veremos que estamos en la nueva
rama llamada edicion_paralelo y master esta como principal

realizamos la secuencia
git status, donde nos indica que estamos en la rama
edicion_paralelo
cambiamos al directorio de /home/msantos/Documentos/Linux
copiamos el archivo unidad_2_linux9.html con otro nombre:
unidad_2_linux9_a1.html
cp unidad_2_linux9.html unidad_2_linux9_a1.html
y editamos el contenido del archivo: unidad_2_linux9_a1.html,
considerando que este es un achivo que alguin adicional esta
tarabajodo por separado
vi unidad_2_linux9_a1.html
copiamos un archivo a esa rama en el directorio del
contenedor Linux/ , regreasmos al contenedor
cd /home/msantos/Documentos/proyecto_git/Linux/
y copiamos el archivo desde el origen a este contenedor:
cp /home/msantos/Documentos/Linux/unidad_2_linux9_a1.html .
solicitamos git status
y añadimos el archivo a la rama: git add
unidad_2_linux9_a1.html
y solicitamos git status

realizamos commit:
git commit -m "archivo paralelo actualizado"
observamos que lo ha comprometido y que fue insertado

usando git log --oneline, revisamos los cambios realizados

para regresarnos a master: git checkout principal y revisamos
el directorio con ls -l y no esta el archivo actualizado con
unidad_2_linux9_a1.html, ya que este esta en la otra rama.

ahora podemos fusionar la rama de edicion_paralelo a master,
para ello debemos estar en master y realizar merge de la rama
que queremos fusionar, con git merge edicion_paralelo, y listo.


NOTA IMPORTANTE: Aqui puse otro nombre
unidad_2_linux9_a1.html, para que se aprecie como se fusiona de
una rama a otra, pero en la parctica el nombre debera ser el
mismo para que se fusione y el archivo contengan los cambios de
los dos, hare lo mismo pero el archivo sera el mismo pero con el
mismo nombre, en la rama edicion_paralelo, primero hare un
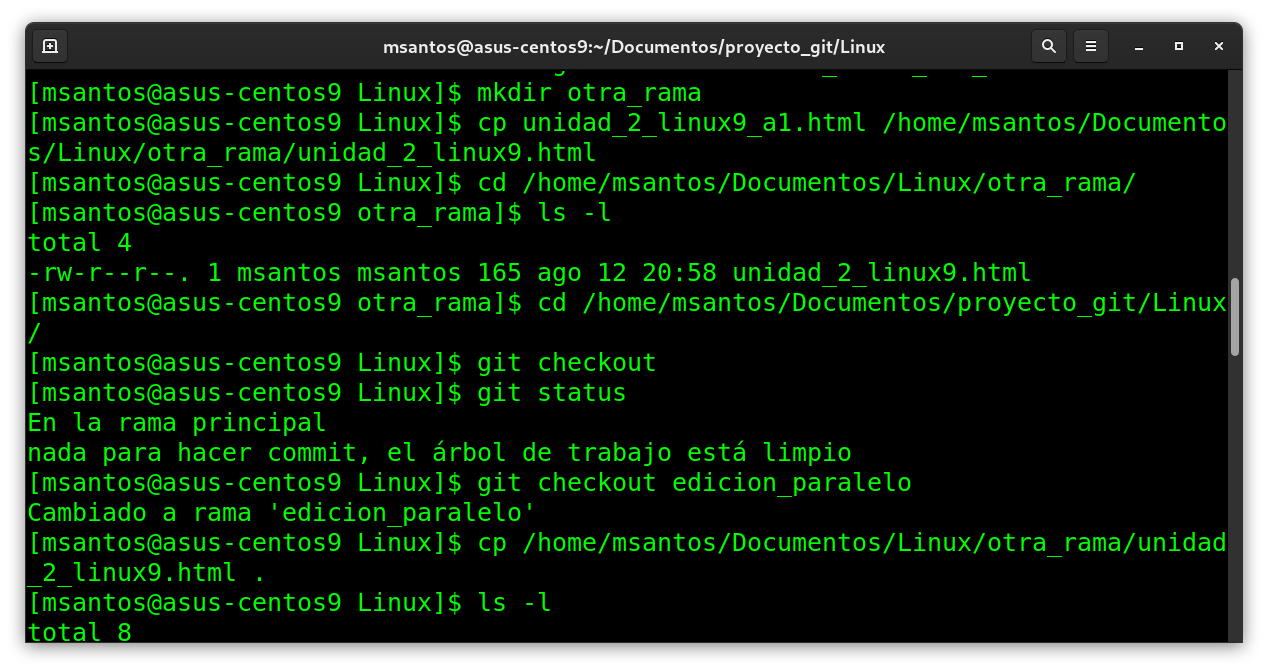
directorio dentro de /home/msantos/Documentos /Linux/otra_rama (
estoy dentro de la ruta : /home/msantos/Documentos /Linux
[msantos@asus-centos9 Linux]$ mkdir otra_rama (creo el directorio)
[msantos@asus-centos9 Linux]$ cp unidad_2_linux9_a1.html
/home/msantos/Documentos/Linux/otra_rama/unidad_2_linux9.html (copio el archivo modificado, con otro nombre,
igual que esta en el contenedor)
[msantos@asus-centos9 Linux]$ cd
/home/msantos/Documentos/Linux/otra_rama/ (me
cambio al dirctorio para confirmar que se copio correctamente)
[msantos@asus-centos9 otra_rama]$ ls -l
total 4
-rw-r--r--. 1 msantos msantos 165 ago 12
20:58 unidad_2_linux9.html
[msantos@asus-centos9 otra_rama]$ cd
/home/msantos/Documentos/proyecto_git/Linux/ (aqui me regreso al contenedor de git)
[msantos@asus-centos9 Linux]$ git status
En la rama principal
nada para hacer commit, el árbol de trabajo está limpio
[msantos@asus-centos9 Linux]$ git checkout edicion_paralelo (me cambio a la rama en paralelo)
Cambiado a rama 'edicion_paralelo'
[msantos@asus-centos9 Linux]$ cp
/home/msantos/Documentos/Linux/otra_rama/unidad_2_linux9.html .
(copio el archivo que me han estado
ayudando del directorio otra_rama)
[msantos@asus-centos9 Linux]$ ls -l
total 8
-rw-r--r--. 1 msantos msantos 0 ago 12 19:54
unidad_1_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_2_anexo1.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_2_anexo2.html
-rw-r--r--. 1 msantos msantos 165 ago 12 20:47
unidad_2_linux9_a1.html
-rw-r--r--. 1 msantos msantos 165 ago 12 21:02
unidad_2_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_3_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 12 17:44
unidad_linux_loc_os.htm
[msantos@asus-centos9 Linux]$ git branch
* edicion_paralelo
principal
[msantos@asus-centos9 Linux]$ git status
En la rama edicion_paralelo
Cambios no rastreados para el commit:
(usa "git add <archivo>..." para actualizar lo
que será confirmado)
(usa "git restore <archivo>..." para descartar
los cambios en el directorio de trabajo)
modificados:
unidad_2_linux9.html
sin cambios agregados al commit (usa "git add" y/o "git commit
-a")
[msantos@asus-centos9 Linux]$ git add
unidad_2_linux9.html
[msantos@asus-centos9 Linux]$ git
status
En la rama edicion_paralelo
Cambios a ser confirmados:
(usa "git restore --staged <archivo>..." para
sacar del área de stage)
modificados: unidad_2_linux9.html
[msantos@asus-centos9 Linux]$ git commit
-m "archivo paralelo actualizado 2"
[edicion_paralelo 771e438] archivo
paralelo actualizado 2
1 file changed, 6 insertions(+)
[msantos@asus-centos9 Linux]$ git checkout principal
Cambiado a rama 'principal'
[msantos@asus-centos9 Linux]$ ls -l
total 8
-rw-r--r--. 1 msantos msantos 0 ago 12 19:54
unidad_1_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_2_anexo1.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_2_anexo2.html
-rw-r--r--. 1 msantos msantos 165 ago 12 20:47
unidad_2_linux9_a1.html
-rw-r--r--. 1 msantos msantos 77 ago 12 21:07
unidad_2_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 10 18:29
unidad_3_linux9.html
-rw-r--r--. 1 msantos msantos 0 ago 12 17:44
unidad_linux_loc_os.htm
[msantos@asus-centos9 Linux]$ git merge edicion_paralelo (se realiza el merge y se combinan los 2 en un
solo archivo)
Actualizando eed8315..771e438
Fast-forward
Linux/unidad_2_linux9.html | 6 ++++++
1 file changed, 6 insertions(+)
[msantos@asus-centos9 Linux]$ git log --oneline
771e438 (HEAD -> principal, edicion_paralelo) archivo
paralelo actualizado 2
eed8315 archivo paralelo actualizado
fadcecd Archivo de la unidad 2 actualizado
c86145a Eliminando manual_datos.txt
1ad79ae CentOS9-archivos
afee332 revision de diseños
[msantos@asus-centos9 Linux]$ cat unidad_2_linux9.html (
// este archivo ha sufrido cambios
// cualquier modificacion sera registrada
// lineas adicionames que "otro" participante agrego para
ayudarnos
con el diseño
[msantos@asus-centos9 Linux]$




Ahora veamos como usar el GITHUB, que es la pagina de GIT
donde podemos subir los repositorios, buscamos con google, git



nos registramos en el servicio:






al seleccionar github, no solicita el nombre del contenedor
haré 2 contenedores 1) main privado llamado Elaboracion_web y 2)
publico Elaboracion-web


conectar a github:



se enviá una verificación de cuenta al correo asignado para
verificar si el propietario es verdadero

creamos nuestro contenedor de forma privada

establecemos el nombre del repositorio:


y llegamos a la pagina principal de github en el contenedor

creamos otro contenedor de tipo publico:

ya podemos comenzar a subir nuestros archivos al contenedor
ve el siguiente video de como subir, commit, y descargar los
archivos del repositorio.
IoT El internet de las cosas (loT, por sus
siglas en inglés) es un sistema de dispositivos de computación
interconectados: máquinas mecánicas y digitales, objetos,
animales o personas que tienen identificadores únicos y la
capacidad de transferir datos a través de una red, sin
requerir de interacciones humano a humano o humano a
computadora, fusionando de alguna manera el mundo digital con
el mundo físico. Gracias a las redes inalámbricas y el bajo
costo de los nuevos procesadores, permite que desde una
aspiradora inteligente hasta un vehículo autónomo, formen
parte de la IoT.
https://www.redhat.com/es/topics/virtualization/what-is-virtualization
(1)
https://blog.desdelinux.net/gnome-boxes-una-excelente-herramienta-de-virtualizacion-open-source/
https://desarrolloweb.com/home/git#track211
https://www.atlassian.com/es/git/tutorials/what-is-git
https://codigofacilito.com/articulos/que-es-git
https://developer.mozilla.org/es/docs/Learn/Tools_and_testing/GitHub#:~:text=Git%20es%20un%20ejemplo%20de,caracter%C3%ADsticas%20de%20administraci%C3%B3n%20de%20proyectos